精读(perhaps)了《A Survey on Multimodal Large Language Models》(IEEE2024)这篇文章有关MLLM的发展历程概括,论文中还给了一个github链接https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models,这篇论文不曾想,点进去就看到了南大的标,并且这篇论文很帅气地写下了这句话:
"To the best of our knowledge, this is the first survey on MLLM."
"据我们所知,这篇综述是MLMM方向的第一篇综述"
![]()
原来是南大发的论文 出于好奇,我搜了一下Mig小组,发现该组有4位老师,其中两位老师恰好是我这个学期计算机系统基础的老师。
9月28日更正:这篇论文的作者来自南大,中科大和腾讯,其中南大的Fu Chaoyou是共一+project leader
LLM,LVM,MLLM
LLM(Large Model) 参数量大,强于推理能力,但是没有视觉
LVM(Large Vision Model)能够理解图像,但是没有推理能力
MLLM(Multimodel Large Langage Model)继承了大参数的特点的同时,使用了新的训练范式。并且在应用场景和功能上进行了扩充:能够读懂多种模态的信息(model)
MLLM Architecture
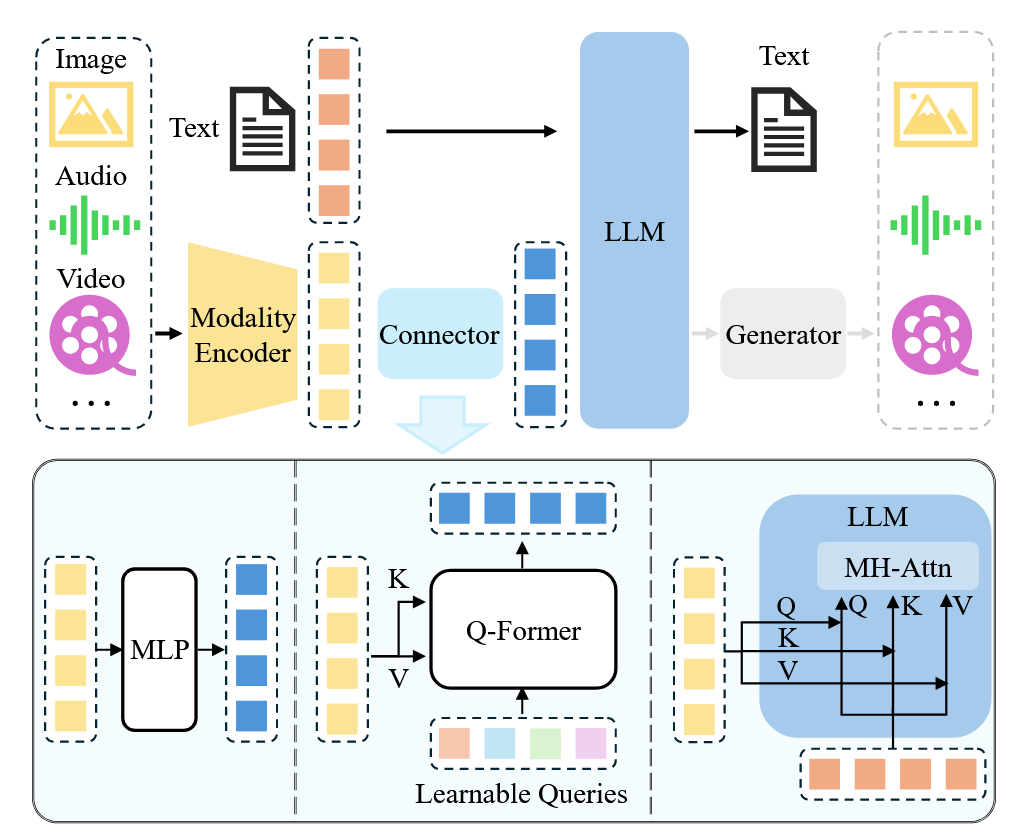
架构图
传统的LLM接受文本作为输入并且输出文本,但是MLLM还需要能够接受并且输出多模态的信息,就需要对多模态的信息做一个处理。主流MLLM再处理多模态的信息的时候,需要用一个特殊的多模态编码器,来把多模态信息转换为LLM可以读懂的信息,最后是LLM的推理和输出,如果是输出多模态的信息需要借助对应的生成器。
预训练模态编码器
作用:把多模态信息(audio、image,video)转换为更加紧凑的表示(more compact representation)通常选取已经在特定模态上已经对齐过的编码器,而非从0开始训练,比如clip在图像-文本信息上进行过对齐,使用这些预训练好的模型更加容易将多模态信息和LLM进行对齐。
预训练大模型
原文对这一部分没有过多地阐述,只提到Scaling Law依旧有效;以及提到MoE架构通过激活部分参数来实现增大模型参数量并且减少计算开销的效果。
多模态交互
补充,前面说编码器不是已经对齐了吗,那为什么还需要connector来连接编码器和LLM?
因为有的编码器没做对齐(如ConvNext)
直接训练end2end的模型开销太大,因此采取需要借助一个中间的媒介来沟通多模态信息和LLM。方法有两个:
- 训练一个connector模块。包括token级别和feature级别的融合:
- token级别:将编码器输出的编码转换成token与文本token拼接后进入LLM。
- feature级别:使用了注意力机制把特征进行融合。
- 使用专家模型:思想是使用专用的模型把其他模态的信息转换为text,但是灵活度不够
这一部分对应论文中的这一张图,最左边是token级别的connector:
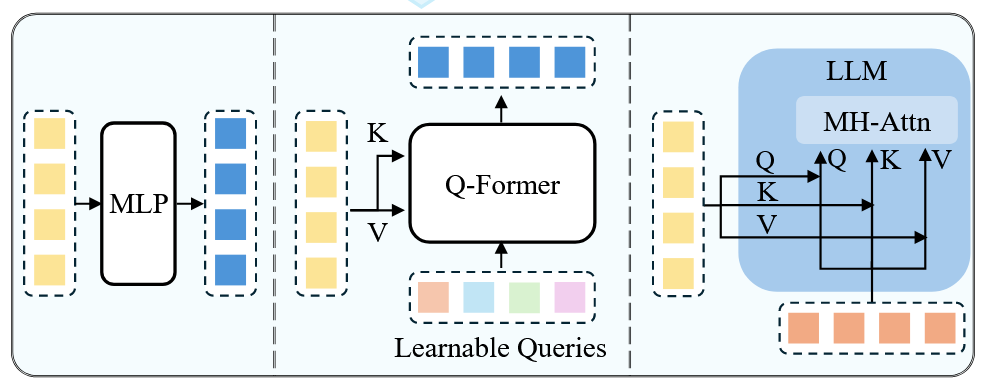
训练策略
预训练Pretraining
预训练的目的有2个:1. 为了让大模型对齐多个模态的信息 2. 让模型获取到外部知识。以图像-文本为例,常见的方法是拿caption数据进行训练,冻结大部分模块,只训练少部分的模块(比如connector)
相关的数据集有:
- Coarse-Grained Data:数据多,但是质量参差不齐,比如CC
- Fined-Gained Data:数量少,并且质量高,比如ShareGPT4V
指令微调Instruction tuning
指令微调是指通过构建指令格式的实例,然后以有监督的方式对大语言模型进行微调,来帮助LLM拥有更好的推理能力, 从而展现出**泛化到未见过任务(zero-shot 0样本)**的卓越能力。
用于指令微调的数据样本可以用这样的一个三元组来表示
数据来源可以是:
- Data Adaptation。把其他相似的任务的数据集改为指令微调数据集,比如把VQA数据集进行扩充和修改
- Self-Instruction。手工写一些数据集,然后用大模型生成更多的数据集。
- Data Mixture:除了多模态指令数据,纯文本的问答对话也可以用于提升对话专业性和指令遵循能力。(不太理解为什么要叫做Data Mixture,也许是把纯文本的对话混合到了多模态的指令微调任务里面?)
对齐微调Alignment tuning
常常用于需要有特定的回复偏好时。Reinforcement Learning with Human Feedback (RLHF) and Direct Preference Optimization (DPO) 是对齐微调的两个主流方法。
**RLHF:**利用强化学习算法让LLM对齐人类需求,通过在训练循环中加入人类监督。以InstructGPT举例,RLHF分为以下三个部分:
- 有监督微调:这一步旨在微调一个预训练模型,以使其输出期望结果,这个微调好的模型被称作policy model。当然也可以直接使用预训练模型,跳过这一步骤。
- 奖励建模:这一步使用偏好对训练一个奖励模型。
- 强化学习(这一步没看懂)
**DPO:**利用简单的二元分类损失从人类偏好的标注中学习。
注: 由于缺乏对强化学习的理解,这一部分只是粗读
前沿拓展技术和相应的应用场景
Multimodal In-Context Learning
- 只需要通过少量样本、可选的指引和外推的新问题进行学习,就能够模型对应样本,解决复杂的问题和未见任务;
- 不需要专门训练,可以灵活引入不同架构。
应用场景:
- 解决多样的视觉推理任务。通常是提供一些特定任务的样例给模型学习,模型泛化到一些新的相似问题上。LLM从样例中学习任务是什么和输出格式是什么,最终生成给定结果。
因为ICL可以通过少量的样本就可以学习新的问题,所以可以学习其他的任务,泛化能力强
- 教LLM使用外部工具。通常涉及更细粒度的信息,由一连串可按顺序执行的步骤组成,以完成任务。与下面的CoT密切相关。
不过我没太看明白这个和多模态有什么关系,我觉得这个更多是ICL的作用,而非MICL,或许应该侧重说明多模态的能力让其能够在更加复杂的环境下进行推理,从而提升agent能力
Multimodal Chain of Thought 多模态思维链
引导LLM一步步思考,回答推理过程,最终输出答案。
思维链在结构方面有单链和的树形链条,前者方法通过一步步推理得到问题-推理过程-答案的链条,后者将问题分解成多个子问题,每个由LLM或者视觉专家模型来生成推理过程,LLM再利用推理过程求出答案。
长度方面,可以分为自适应长度和预定义长度
LLM-Aided Visual Reasoning(LLM 辅助视觉推理)
主要是在agent方面的应用
这类方法的核心是引入外部工具或视觉模型,让 LLM 成为任务的“助手”。它们既可以针对特定任务设计,也能做成通用系统。和传统的视觉推理模型相比,这些系统有几个显著的优势:能更好地泛化到新对象和新概念,能够借助 LLM 的强大推理实现复杂任务,还能提供更自然的交互方式和更灵活的控制。
在训练方式上,大体可以分两类:
- 一种是不需要额外训练,直接通过 prompt 驱动 LLM 来完成任务。
- 另一种方式是微调,通过给模型额外的工具使用数据集,提升它在调用工具、定位等方面的能力。GPT4Tools 就是通过收集新的工具相关指令数据,进行 instruction-tuning 来改进系统表现。
LLM 在这些系统里面有这些作用:
- LLM as a Controller.:把复杂任务拆解成更小的子任务,并分配给合适的模块去执行。这里通常会用到链式思维(CoT),比如 VisProg 就要求 LLM 输出一个视觉程序,每行都对应调用一个模块,还要附带参数。这类方法经常借助少量手工示例作为参考。
- LLM as a Decision Maker.:总结上下文和历史信息,判断当前是否有足够信息来完成任务。如果没有,就继续获取信息;如果够了,就组织和整理出用户友好的答案。
- LLM as a Semantics Refiner.:利用 LLM 的语言和语义能力,把零散的信息整合成连贯自然的表述,或者根据用户需求调整生成的文本。
前沿文章摘要
Multi-Layer Visual Feature Fusion in Multimodal LLMs: Methods, Analysis, and Best Practices https://arxiv.org/abs/2503.06063
tags:特征融合
本文系统研究了多层视觉特征在多模态大模型中的融合方法,首次提出针对视觉层次选择和融合策略的系统化分析。作者发现从起始、中期和末期各选择一层作为融合输入能够获得最佳效果,并验证了“直接在输入端融合多层特征”优于在内部层融合等方案。这些发现为构建高效的视觉-语言模型提供了实践指南,是提升多模态LLM性能的新思路
Benchmarking Multimodal Retrieval Augmented Generation with Dynamic VQA Dataset and Self-adaptive Planning Agent https://arxiv.org/abs/2411.02937
tags: 多模态信息检索
本文针对多模态检索增强生成(mRAG)提出了新的评测框架和方法。作者创建了 Dyn-VQA 数据集,引入需动态检索的复杂问题,挑战传统的固定检索流程。研究发现现有mRAG方法难以应对此类问题,于是提出了 OmniSearch 自适应检索规划器,能够将复杂问题动态拆分成子问题并逐步检索答案。该方案在实验中显著优于传统方法,推进了多模态RAG的研究前沿
SViQA: A Unified Speech-Vision Multimodal Model for Textless Visual Question Answering https://arxiv.org/abs/2504.01049
tags: audio generation
本文提出了首个语音-视觉统一模型SViQA,直接处理口语提问而无需转换为文字,填补了现有模型多聚焦于文本-视觉融合的空白 。
后记与补充:
- 上个学期使用过zotero但是当时不知为何十分卡顿,今天尝试多个方案解决问题,最后发现的问题是:我把zotero的默认下载路径改到D盘。。。后续删除重新再C盘默认路径下载之后解决了问题。(使用zotero版本为7.x)
- 目前使用ob来管理笔记,使用zotero阅读文章,缺少联动的方法。
- 我发现自己了解过的相关知识阅读起来就很舒服,一旦在一大段里面多次出现自己不理解的概念,读起来就很难受了。
- 接上一条所说的,读论文会发现自己还有相当多的知识没有搞懂,一篇论文会涉及到诸多方面的内容,比如这篇讲多模态方面的论文,就涉及到了Cot,ICL,RLHF,指令微调、对齐微调等等内容,而我连基本的模型都写不了😂
下一阶段计划:
- 学一些基础知识(模型训练全流程,基础的神经网络结构)
 chatGPT给我的年度诗篇 ```text
chatGPT给我的年度诗篇 ```text