PPT里面的内容不要写不会的, 主要根据PPT里面的内容+助教给的问题进行提问
小组汇报
3-5个问题:
所有人都要上台,问题谁回答都行。 汇报人数自行安排
录音中提到的核心讨论问题
1. 关于NEMO论文的锚帧选择:为何选择这些矛盾,以及这些矛盾的重要性。锚帧经超分辨率增强后的收益,通过何种技术传递给其他帧。 2. 4篇论文X3个模块都有一个问题->需要准备设计的理念,每一个模块为什么要这么设计。
书面汇报
每一个人自己写一份,使用老师发的报告
前言 主题 发展的过程,
那四篇论文是一定要出现在综述里面
可以按照综述的思路,把不同的论文按照实现思路实现不同的
添加参考文献
如果有手工画图,手工用PTT/AI画图,来获得更高的分数
最后要有一个课程收获,对课程的收获,
尽量多写一些,反正也不是自己写的
不要出现简单的错误,
works
NAS
- 针对每一个视频都训练dnn模型
- 然后在client端根据ABR算法选择合适的码率和dnn模型
- 在client端进行超分 暴力地计算每一帧,不适合在手机等设备上使用.
NEMO
NEMO applies neural super-resolution to a few select frames and transfers the outputs to benefit the remaining frames. The frames to which super-resolution is applied are carefully chosen to maximize the overall quality gains. NEMO leverages fine-grained dependencies using information from the video codec and strives to provide guarantees in the quality degradation compared to per-frame superresolution.
NEMO在server端用算法选择anchor frame,然后在client端可以超分这些anchor frame,这些变成高清的锚点帧会被存入缓存。对于那些没有跑 AI 算法的普通帧(非锚点帧),手机会利用视频编码的特性,直接从缓存的高清锚点帧中复用像素信息来提升画质。 NEMO consists of two novel components. First, at the serverside, the media server analyzes a video to select frames to apply super-resolution for maximizing the quality gains. This information is captured in what we call a cache profile, provided to clients alongside the video content at the beginning of each streaming session. Second, at the client-side, by referring to the cache profile, the mobile client applies neural super-resolution to the select frames, referred to as anchor points. Anchor points that have been up-scaled using super-resolution are cached so they can be reused for up-scaling non-anchor frames. Creating a full-fledged system that achieves video super-resolution at real-time on mobile devices, however, involves solving a number of non-trivial challenges:
- First, to transfer the benefit of neural super-resolution of select frames to the entire video, we leverage fine-grained information from a video codec regarding frame dependencies. However, this must be done carefully to maximize the computational savings without drastically compromising the quality.
- Second, anchor point selection greatly affects the video quality. However, the number of possible sets of anchor points are on the order of 2|f rame |, making exhaustive search infeasible.
- Finally, mobile devices are heteregenuous with varying computing capacities. The system must be able to adapt to various mobile devices to enable real-time video super-resolution on devices ranging from hig
- 挑战一:画质与计算量的平衡 (Quality vs. Savings)
- 原理:虽然可以利用视频编解码器(Codec)中帧与帧之间的依赖关系来传递超分辨率的效果,但这种“传递”是有损耗的。
- 难题:如何精准计算,既能省下大量的手机算力,又不至于让画质大幅下降?
- 挑战二:锚点帧的选择难题 (Selection Complexity)
- 原理:视频有很多帧,选择哪些帧作为锚点效果最好?
- 难题:如果有 $n$ 帧,可能的组合就有 $2^n$ 种(指数级爆炸)。服务器不可能靠穷举法来尝试每一种组合,必须找到一种高效的搜索算法。
- 挑战三:设备性能的异构性 (Device Heterogeneity)
- 原理:有的手机(如高端旗舰)算力强,有的手机(如低端机)算力弱且容易发烫。
- 难题:系统必须具备弹性,能够根据不同手机的性能实时调整。比如在高端机上多选几个锚点(画质更好),在低端机上少选几个(保证不卡顿、不发烫)。
Adaptive Bitrate/Streaming
根据网络环境自动选择不同的码率,但是从根本上来说,还是受限于网络带宽。并且是一种用体验质量换取流畅度的做法。
Super Resolution
如果用超分的做法,那么对client端的开销比较大,对于移动设备不是很友好
Conten-Aware neuarl adaptive streaming
- NAS采用的是每一个视频都训练一个dnn模型,之后由client端结合ABR来选择不同的比特率然后决定是否要下载dnn模型,在本地进行推理运算将低分辨率的视频转成高分辨率的视频。
- 但是这个做法在mobile device上是不行的,因为需要GPU
NEMO论文问题:
- 毛帧选择算法
- maozhen怎么通过SR增强传递给其他帧
- 每一个模块为什么要这么设计?启发是什么?
what to cache?
在DNN中,超分延迟最高、计算开销最大的是后面的几层,因此NEMO cache了模型的最后输出(也就是最后得到的超分图像)we cache the final output
To maximize the benefit of reuse, we carefully transfer/reuse the pixels of cached frames using fine-grained frame dependencies (ğ4.2) and select an optimized set of anchor points that delivers the largest overall quality improvement (ğ4.3). 之后,根据frame之间的依赖关系,复用前面cache过的SR图像,来提升其他未被超分的帧质量。
anchor frame如何将增强效果传递给其他的帧?(即,如何reuse 已经cache的frame)
想要复用已经cache的帧,那么就需要找到和当前帧最相似的那个cache frame,并且找到每一个像素如何借用对应的帧。
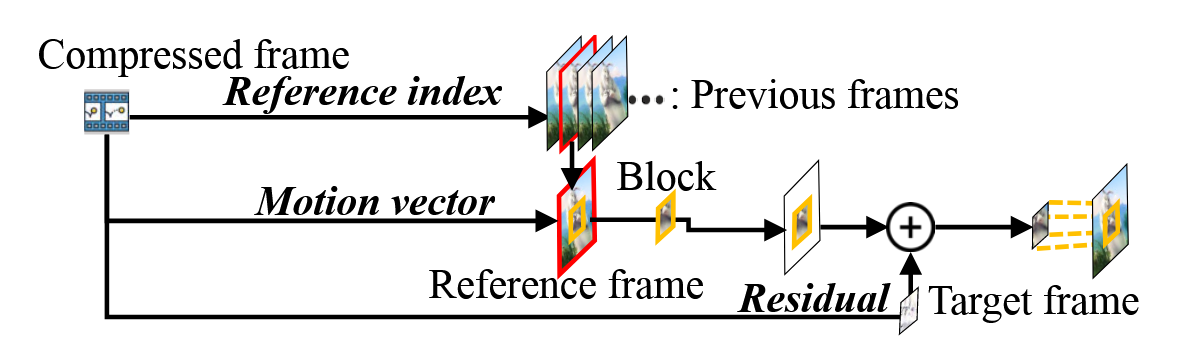
实际上在client对视频进行解码的时候,就已经保存帧之间的关系(参考索引reference index、运动矢量 motion vector、残差 resudual等) (其中,参考索引告诉解码器去参考那一帧,运动矢量告诉解码器是从哪个位置移动过来的,残差告诉解码器移动过来的像素和真实的像素之间还差多少。)
NEMO实现了一个集成了SR的解码器:
- 如果是anchor frame那么跑dnn并且把结果cache
- 如果不是anchor frame,那么根据reference index取得高清帧,然后根据motion vector把像素挪过去,再加上resudual的部分。
SYSTEM DESIGN
Offline / Server side
将上次的视频按照不同的bitrate进行压缩,并且选取合适的anchor frame,生成不同的cache profile,训练不同参数的dnn模型。
Online / Clinet side
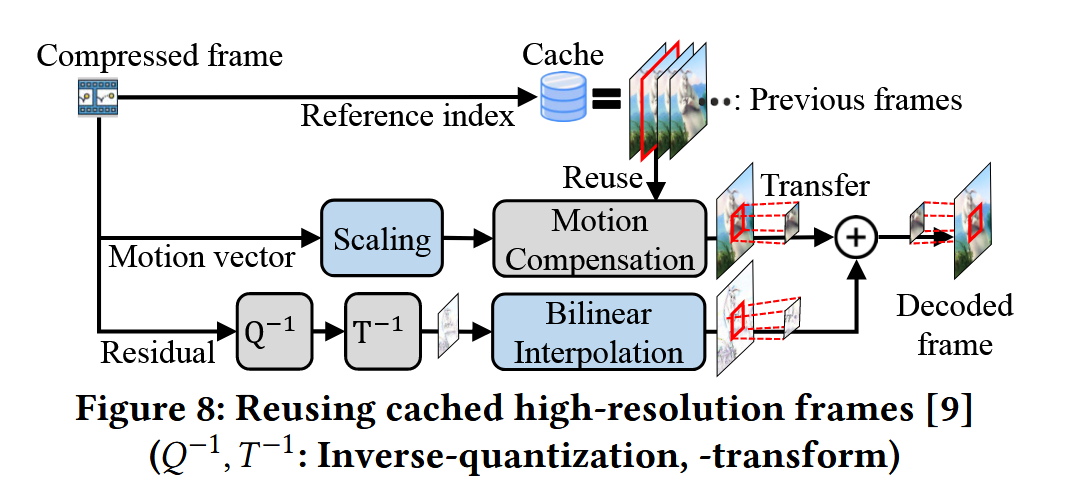
修改了标准解码器,如果是anchor frame那么就调用dnn进行跑sr,然后缓存。 如果不是anchor frame,就从解码器中取出motion vector,和residual,复用缓存的高清帧。
如何复用解码器?
如何选择anchor frame?
NEMO 提出了一个关键假设——“一个非锚点帧的画质,主要取决于参考集中对他贡献最大的那个锚点”。 贪心算法流程:
- 初始化:计算所有只含 1 个锚点的方案的画质。
- 迭代增加:每次选出一个能让当前整体画质提升最大的帧,加入锚点集。
- 停止条件:直到当前组合的画质与“逐帧跑 AI”的画质差距小于 0.5 dB(或其他阈值)。
每一个模块为什么要这么设计?启发是什么?
对于SR集成的解码器
目的是为了尽可能地减少超分的次数,降低运算开销。利用解码器中帧之间的关系(reference index,move vector和residual)来尽可能地利用cached anchor frame
启发就是借助视频解码过程中对帧关系的描述来辅助帧的高清重建
锚帧的选择
利用“最大质量增益近似”公式,把指数级搜索简化为贪心搜索。每次只选那个能让整体画质提升最大的帧,直到达到 0.5dB 的画质损耗限制。这保证了每一分算力都花在了刀刃上。
为什么要设计cache profile?
简化server和clinet的协同,同时减少client的开端,
NAS论文
问题
- 什么是机器学习没有免费午餐定理?
- 为什么要使用可扩展的超分辨率模型结构,如果不使用的话,会产生什么问题?
- 在NAS中用户产生的视频是无限的,但是超分辨率模型的容量是有限的,这个问题是如何解决的。
前面付云锋同学介绍了神经增强技术在视频点播当中的应用,下面由我来介绍在直播领域如何应对这个问题
[!NOTE] SLIDES1: Ingest Bottleneck
尽管NAS和Nemo等研究已经在视频点播领域解决的很好了, 但是直播的实时性决定了 没法像NEMO和NAS一样提前训练超分dnn模型所以 LiveNAS采用在线学习机制以最大化质量增益,并依据实时质量提升动态调整资源使用。
LiveNAS
不同于使用预训练的通用模型,LiveNAS 在直播过程中实时训练针对当前视频内容的深度神经网络(DNN)。
[!NOTE] slides2-LiveNAS Ingest Client Side 讲Ingest Client Side
LiveNAS 的核心思想是在线训练(Online Training)。给每一个直播间都训练一个专属的dnn模型, 将从主播端的低分辨率视频超分为高分辨率的视频流,之后推送给用户. 大大减少了对主播端的要求 为了让服务器训练出专属于当前直播间的模型,主播端不仅要推流,还发送少量的 高质量原始画面补丁(Patches)作为训练的“真值”(Ground Truth)
A. 摄入客户端 (Ingest Client - 主播侧)
为了支持在线学习,客户端不仅发送编码后的视频流,还发送少量的**高质量原始画面补丁(Patches)**作为训练的“真值”(Ground Truth)。
- 质量优化调度器 (Quality-Optimizing Scheduler): 动态平衡上行带宽的分配。它决定多少带宽用于传视频流,多少带宽用于传训练用的Patch,以最大化最终的视频质量。
因为带宽是固定的,所以用于上传视频流的内容多了,那么能上传ground truth的高清帧patch就相应的会变少. 上次的补丁少->DNN训练不足,超分效果不好; 但是如果是patch太多,又会导致分配给视频流的码率变低. 带宽的分配是也是一个trade-off的问题. paper中实现了一个优化器来选择最合适的比例,
Patch Selection Overview
- 补丁采样器 (Patch Sampler): 智能选择最能提升模型训练效果的图像区域(例如编码失真严重的区域),而不是随机选择或者选择整个帧。
即使调度器分配了带宽,这部分带宽也非常小(通常只有视频流的10%左右)。如果直接发送全分辨率的原始帧,带宽瞬间就爆了。client端会把元素patch和压缩之后的patch进行对比,选择那些失真很严重的patch对其然后进行JPEG的有损压缩,进一步地将patch的大小进行压缩.
- 宏观上用调度器:选择在“保证当前画质(发送视频流)”和“投资未来画质(发送patch训练DNN)”之间找到数学上的最优带宽分配平衡点。
- 微观上用采样器:在极其有限的带宽预算内,利用分块(Patching)、筛选(只传难编码区域)和压缩(JPEG)技术,将最有价值的训练数据传输给服务器。
[!NOTE] slides3-LiveNAS Media Server 讲media server side
LiveNAS Media Server Design
在服务器端,LiveNAS 实现了 Content-Adaptive Online Learning(内容自适应在线学习)。
- 内容自适应训练 (Content-Adaptive Online Learning):
- 利用客户端传来的Patch实时训练超分辨率模型。
- 资源优化: 当检测到画质提升饱和(再训练也没用了)或者场景未发生变化时,会自动暂停训练以节省GPU资源;当场景切换时通过检测Patch误差自动恢复训练。
- 超分辨率处理器: 利用训练好的模型将低分辨率的推流(如360p/720p)实时超分至高分辨率(1080p/4K)。支持多GPU并行处理以降低延迟。
这里我到时候再看看吧
LiveNAS通过针对直播场景在线学习dnn模型,很好地缓解了主播端带宽不足的问题. 但是, LiveNAS, 和NAS一样,都是需要对每一帧进行超分,运算开销太大. 并且, 想要把主播端的低清视频流超分为高清视频流,需要先把低清视频流解码,然后对每一帧进行优化,然后在编码为高清视频流. 编码高清视频的压力同样是不可忽略的. 这就导致了对media server高性能,以及对用户稳定带宽的要求. 从这些瓶颈出发, NeuroScaler优化了算法和资源调度.
NeuroScaler: Neural Video Enhancement at Scale
zero-inference 的anchor frame 是怎么样的 什么是混合视频编码 视频编码器的残差是什么? 在视频编码器怎要的?
既然全帧超分太贵,我们就只做选择性超分。 前面讲的时候NEMO可以通过选择anchor frame并cache,然后加以复用,从而避免了对所有的帧加以超分。 但是这个方法不适合直播(因为直播场景没法预先训练一个dnn模型然后再到client端进行推理)
NEMO 的方法依赖于Heavy Offline Computation(昂贵的离线计算)来做决定,而 NeuroScaler 做到了 Online & Zero-inference(在线且零推理)。
[!NOTE] slides4-Neuro Scaler: Anchor Frame Selection 讲 Neuro Scaler怎么选帧
Zero-inference Anchor Frame Selection
NEMO提出了选择性超分:只增强关键帧(Anchor Frames),其他帧通过重用这些关键帧的像素来生成。但是矛盾之处在于,NEMO需要对所有帧都跑一遍推理,然后通过贪心算法选择增益最大的帧,但是在live的场景下,我们没法这样做。所以我们需要一种方法,不需要运行神经网络就能选出关键帧。
- 动机:为了解决live环境下选帧困难的问题(没法像nemo一样选帧) First, to accelerate video superresolution, it extends selective super-resolution but presents an online algorithm that chooses frames to apply super-resolution (i.e., anchor frames) using codec-level information in real time 使用视频编码器的的数据来实时选择需要对哪些frame进行增强。 选帧的速度比NEMO要快。
在选定了一帧之后,后续的相关帧通过motion vector和residual来推算出来,如果residual很大且距离下一个关键帧的距离很长,说明和参考的anchor frame的差别就很大,这个时候考虑在这一帧处进行加.
收益 = 残差减少量 × 持续帧数
选择的方法是:
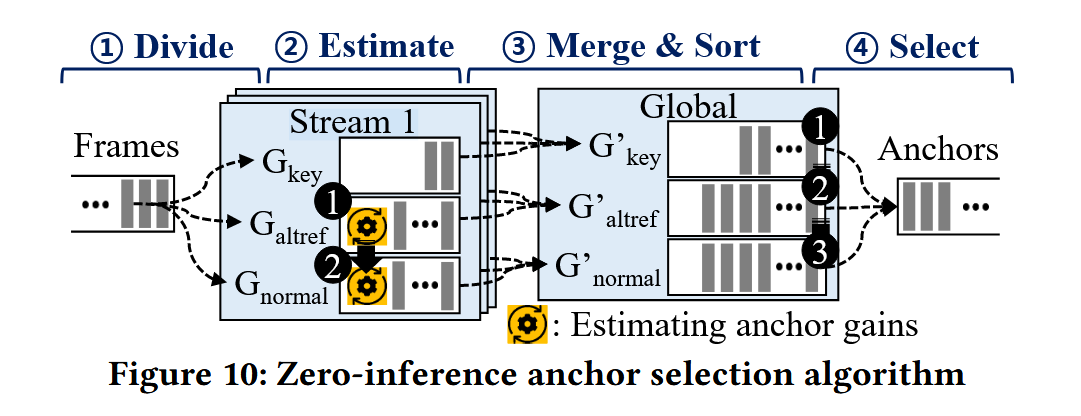
Dive
把每个直播流里的帧按类型分成三个等级的桶:
GkeyGkey(最高优先级):关键帧。GaltrefGaltref(中优先级):替代参考帧。GnormalGnormal(低优先级):普通帧。根据帧的类型,把视频帧扔进三个优先级的桶里:关键帧 (Key) > 替代参考帧 (Alt-ref) > 普通帧 (Normal)。
Estimate
针对每一帧进行估算,计算如果将其进行超分能够带来的收益.
收益 = 残差减少量 × 持续时长
Merge & Sort
将所有处理的直播流都汇聚在一起,按照等级分为多个全局帧池. 然后每一个池的内部,按照前面估算的收益值进行排序
select
优先选择关键帧,然后贪心地再从alt-ref 池子里面选择收益最高的,直到把GPU占满为止
Hybrid Video Codec
- 思路: 解决“重编码”太慢的问题。
即使你有无限快的 GPU 做完了超分推理,把这些生成的 4K 图片重新编码成视频流也是极其缓慢的。这个也是一个瓶颈 即使 GPU 秒级完成了超分,把 4K 图片重新编码成视频流(Re-encoding)也是极慢的,这往往会成为新的瓶颈。
不要重新编码整个视频
- 思路: 不要重新编码整个视频!
- 做法:
- 直接复用原始的低清视频流。
- 把那些经过超分增强的 Anchor Frames,作为独立的图片(Image Codec)进行压缩。
- 把“低清视频”+“高清图片”打包发给客户端。
- 客户端播放时,用高清图片替换对应的低清帧,并利用运动向量(Motion Vector)把清晰度“传播”到后续帧。
采用混合视频解码器,复用旧视频,把那些anchor frame作为独立的图片用图像编码器进行压缩,然后把低清视频和anchor frame超分后的图像内容一起发送给client。
client解码时,利用高清的锚点帧作为参考,结合低分流中的运动向量,在本地轻量级地恢复出高分视频。
[!NOTE] slides5-Neuro Scaler: Resources Management 讲 Neuro Scaler怎么调度GPU资源
Anchor-aware Resource Management
异构性,不同的视频流的处理方式不同(有的是360p->720p,有些是720p->4K),对于的计算开销也不也一样。即便在同一个视频里面,有一些帧的变化多,有一些帧的变化小。 如果只是简单的把视频按照轮询的方式,分配给不同的GPU,很有可能导致存在负载不均的情况,有些GPU资源闲置,但是有些GPU运算过负荷。
它抛弃了传统的“按流分配”,提出了“按锚点帧分配”的调度策略。 结合前面选帧的策略, 按照当前集群的算力情况,来最大限度地聪明global的帧池里面选择帧. 让整个平台的总画质达到最大化.
选中锚点帧后,调度器不会把“整个视频流”发给某个 GPU,而是把一个个独立的锚点帧任务分发给空闲的 GPU 实例。 这样可以完美地实现GPU的负载.
GPU Context Switching
而如果把原本对视频流的处理改为对选定的anchor frame的处理,那么GPU就需要频繁地切换DNN模型, 那么就需要GPU频繁地集训上下文切换,也会有不可忽略的开销 提前把模型进行预编译好,在GPU上放上一个空的模型,然后在运行的时候,就只需要把参数给填上去.
总结一下,LiveNAS解决的是引入了在下学习,对每一个直播间都训练一个dnn模型.
一些技术名词
Neural-enhanced Streaming
streamer(主播)如果网络情况不好,那么上传的视频很糊,影响观感。 因此在media server端对视频流线decode 再 SR,再encode为视频流。 但是这样的计算开销太大了。 并且在media server端,巨大的资源调度也是一个问题。
 chatGPT给我的年度诗篇 ```text
chatGPT给我的年度诗篇 ```text