ICS实验报告
PA4 - 虚实交错的魔法: 分时多任务
学生: 雷业成 (241220106)
南京大学计算机科学与技术系
邮箱: 241220106@smail.nju.edu.cn
2025 12 09
请直接看最后面的必答题!
多道程序
为什么需要使用不同的栈空间?
如果不同的进程共享同一个栈空间, 会发生什么呢? 会相互干扰,因为进程的许多信息就保存在栈空间上。
上下文切换
实现上下文切换
根据讲义的上述内容, 实现以下功能:
- CTE的
kcontext()函数 - 修改CTE中
__am_asm_trap()的实现, 使得从__am_irq_handle()返回后, 先将栈顶指针切换到新进程的上下文结构, 然后才恢复上下文, 从而完成上下文切换的本质操作
正确实现后, 你将看到yield-os不断输出?, 这是因为我们还没有为kcontext()实现参数功能, 不过这些输出的?至少说明了CTE目前可以正确地从yield-os的main()函数切换到其中一个内核线程.
Context *kcontext(Area kstack, void (*entry)(void *), void *arg) {
Context* context = (Context*)(kstack.end - sizeof(Context));
context->mepc=(uintptr_t)entry;
context->gpr[10]=(uintptr_t)arg;
context->mstatus=0x1800;
return context;
}
在trap.S中加上
call __am_irq_handle
# 把sp指向__am_irq_handle ret的地址
mv sp, a0
在Nanos-lite中实现上下文切换
实现以下功能:
- Nanos-lite的
context_kload()函数(框架代码未给出该函数的原型), 它进一步封装了创建内核上下文的过程: 调用kcontext()来创建上下文, 并把返回的指针记录到PCB的cp中 - Nanos-lite的
schedule()函数 - 在Nanos-lite收到
EVENT_YIELD事件后, 调用schedule()并返回新的上下文
Nanos-lite提供了一个测试函数hello_fun()(在nanos-lite/src/proc.c中定义), 你需要在init_proc()中创建两个以hello_fun为入口的上下文:
void init_proc() {
context_kload(&pcb[0], hello_fun, ???);
context_kload(&pcb[1], hello_fun, ???);
switch_boot_pcb();
}
其中调用switch_boot_pcb()是为了初始化current指针. 你可以自行约定用何种类型来解析参数arg(整数, 字符, 字符串, 指针等皆可), 然后修改hello_fun()中的输出代码, 来按照你约定的方式解析arg. 如果你的实现正确, 你将会看到hello_fun()会轮流输出不同参数的信息.
在实现context_kload和context_uload的系统的协同交互的时候,遇见了一些问题:
void init_proc() {
switch_boot_pcb();
Log("Initializing processes...");
// load program here
// naive_uload(current, "/bin/comprehensive-test");
// naive_uload(current, "/bin/bmp-test");
// naive_uload(current, "/bin/menu");
// naive_uload(current, "/bin/bird");
// context_uload(&pcb[0], "/bin/bird");
// naive_uload(current, "/bin/coremark");
// naive_uload(current, "/bin/typing-game");
// naive_uload(current, "/bin/fceux");
// naive_uload(current, "/bin/171860508");
// context_kload(&pcb[0], hello_fun, "");
// context_uload(&pcb[1],"/bin/pal");
// context_uload(&pcb[0], hello_fun, "");
// context_kload(&pcb[1], hello_fun, "");
// context_kload(&pcb[0], hello_fun, "");
context_kload(&pcb[0], hello_fun, "");
context_uload(&pcb[1],"/bin/pal");
nr_proc=2;
}
Context* schedule(Context *prev) {
int cur_idx=(current>=pcb&¤t <pcb + nr_proc) ? (current - pcb) : -1;
if (cur_idx >= 0) {
current->cp = prev;
}
int next_idx = (cur_idx + 1) % nr_proc; // cur_idx==-1 时从 pcb[0] 开始
current = &pcb[next_idx];
Log("Schedule Called Context prev=%x now=%x cur_idx=%d next_idx=%d", prev, current->cp, cur_idx, next_idx);
return current->cp;
}
两个hello程序相互yield进行切换是OK的,但是换成一个navy-app和hello程序进行切换就不行了。
加上更多的调试信息发现:
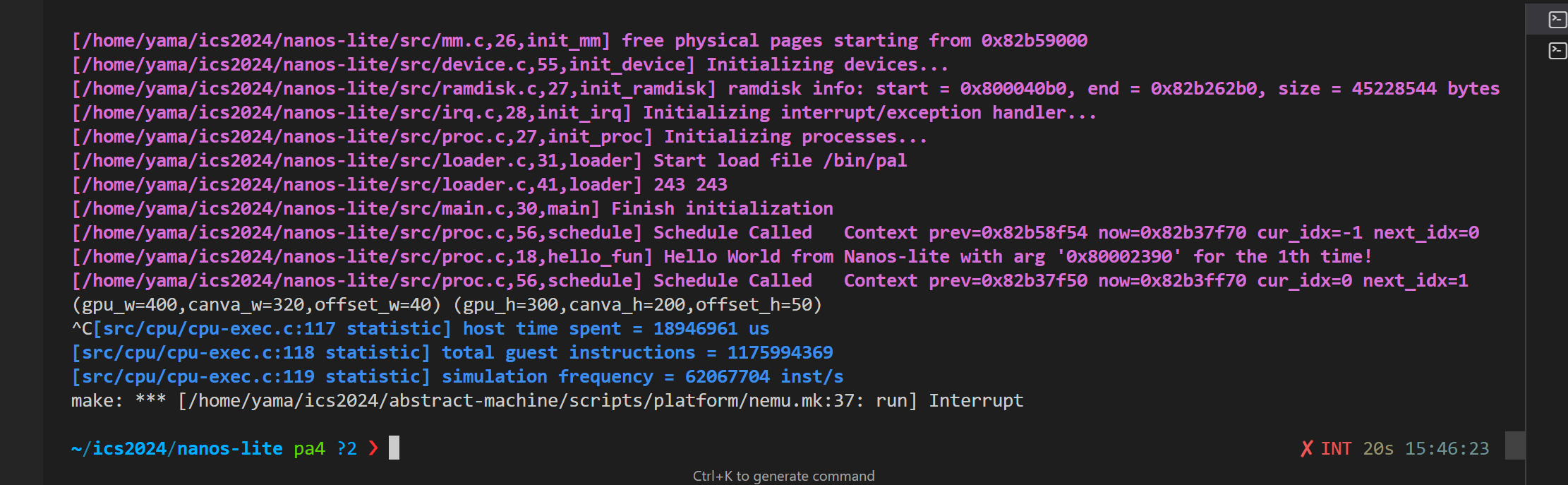 从hello程序到navy-apps是正常地,说明是navy-apps到hello_func出现了问题
从hello程序到navy-apps是正常地,说明是navy-apps到hello_func出现了问题
想了一下应该是在应用程序的时候没有主动yield,奇了个怪,手册也没有告诉我要做这一步?

之后,在IOE调用前,先yield进行调度(在 serial_write(), events_read(), fb_write() 的开头加上 yield();)
成功实现:
 不过感觉速度比以前要慢一些。
不过感觉速度比以前要慢一些。
一山不能藏二虎?
尝试把hello_fun()换成Navy中的hello:
-context_kload(&pcb[0], (void *)hello_fun, NULL);
+context_uload(&pcb[0], "/bin/hello");
context_uload(&pcb[1], "/bin/pal");
你发现了什么问题? 为什么会这样? 思考一下, 答案会在下一阶段揭晓!
会报错:
[/home/yama/ics2024/nanos-lite/src/proc.c,27,init_proc] Initializing processes...
[/home/yama/ics2024/nanos-lite/src/loader.c,31,loader] Start load file /bin/bird
[/home/yama/ics2024/nanos-lite/src/loader.c,41,loader] 243 243
[/home/yama/ics2024/nanos-lite/src/loader.c,31,loader] Start load file /bin/pal
[/home/yama/ics2024/nanos-lite/src/loader.c,41,loader] 243 243
[/home/yama/ics2024/nanos-lite/src/main.c,30,main] Finish initialization
[/home/yama/ics2024/nanos-lite/src/proc.c,57,schedule] Schedule Called Context prev=0x82b58f54 now=0x82b37f70 cur_idx=-1 next_idx=0
address (0xfffff91c) is out of bound at pc = 0x83008900
我的想法是: 两个应用程序在laod的时候都被转载到了对应的空间去了,因为两个程序自己的虚拟存储肯定是有重叠的(因为都是从0x8048000开始装.text等等)而目前的额PA还没有实现好多个程序的怎么映射到不同的物理内存中,所以会有这个问题。
实现带参数的execve()
在做这一部分的时候,被自己无语到了: 找bug找了2天,逻辑反复修改、检查,
另外,之前一怒之下把fsimg全部给删了,然后一直显示缺少字体。 之后才发现原来share目录下的文件需要自己去补全回来🤯 然后聪明的我想到用curl下载,然后我就成功地把curl到的html给下载了下来。。。并且因此debug了很久;最后发现这个文件的offset很小才意识到不对劲
执行exec-test的结果:
运行了很多次之后,挂掉了,内存超了
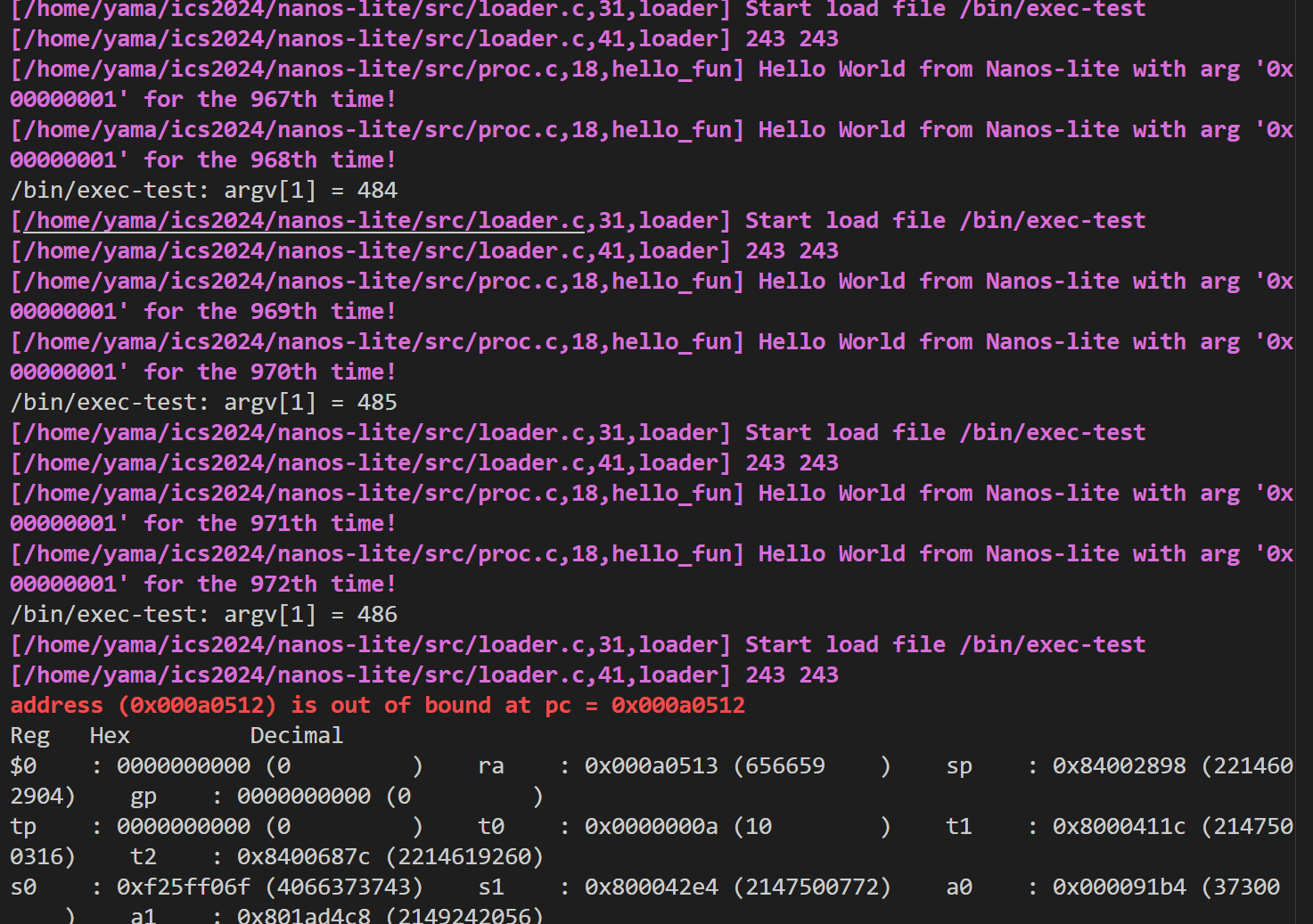
还有个地方比较坑的是:貌似PAL就没有实现识别skip的功能? 读了源代码才发现这个,于是加上:
bool skip_anime=false;
for(int i=0;i<argc;i++){
printf("Arg[%d]=%s ",i,argv[i]);
if(strcmp("--skip",argv[i])==0){
skip_anime=true;
}
}
if(skip_anime){
printf("Deteched skip!");
}
printf("\n");
...
if (!skip_anime) {
PAL_TrademarkScreen();
PAL_SplashScreen();
}
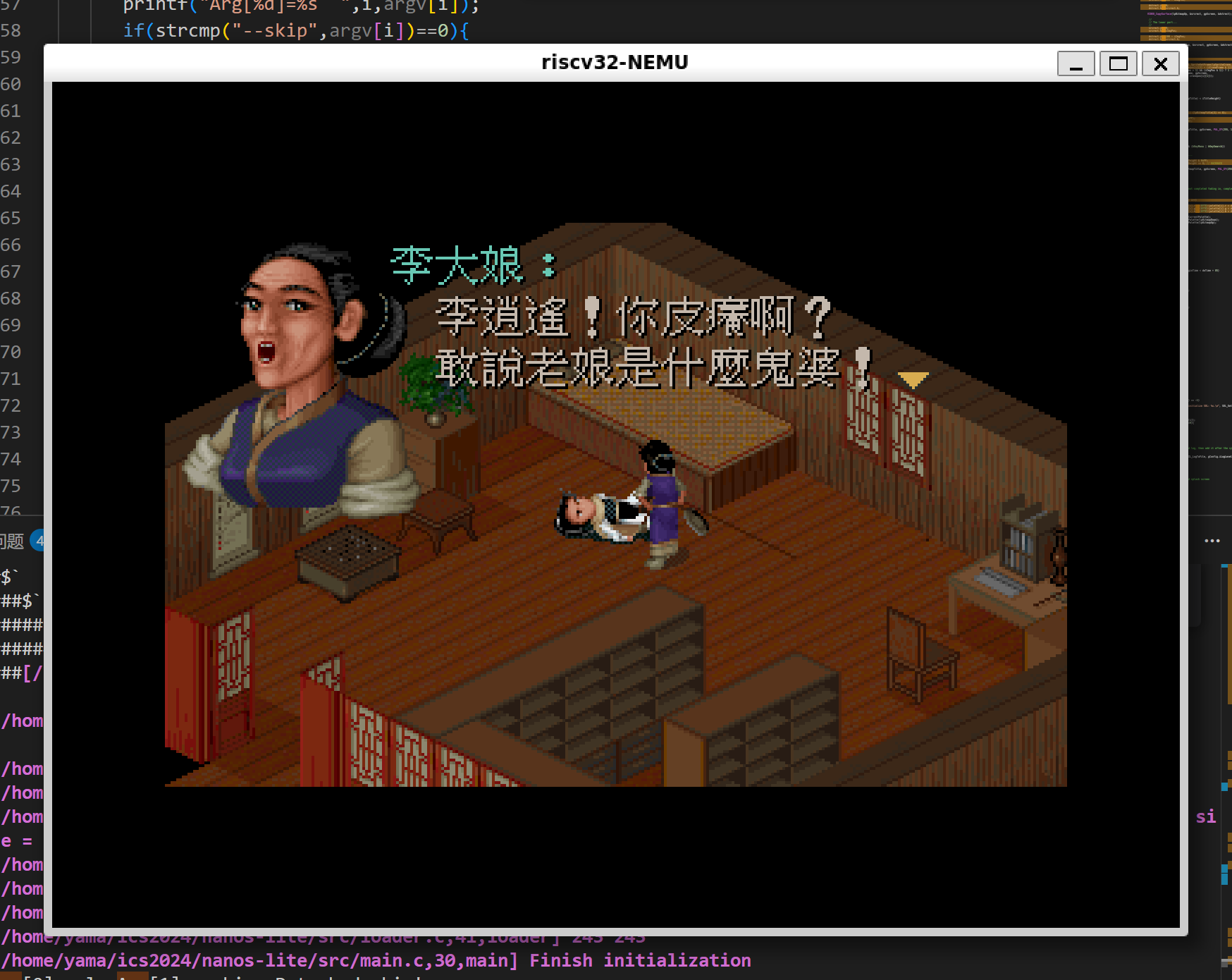 开心,这下可以直接进入游戏了!
开心,这下可以直接进入游戏了!
我想的是context_uload() 一开始就 loader(pcb, filename),在 非 VME 下所有用户程序共享同一个地址空间,所以在nterm 调用 execve("/bin/pal", argv, ...)
- 内核进入 context_uload() 先把 pal ELF 加载到 0x84000000 这一步会覆盖掉 nterm 自己的 .data/.bss(包括你 shell 里保存的 argv[] 数组、字符串缓冲区等)于是后面再 strlen(argv[i]) 时,argv[i] 已经不是字符串指针了 但是为什么实验手册又要求我们这么做呢?
最后的解决方案是: 我把 nanos-lite/src/proc.c 的 context_uload() 改成:
- 先把 filename/argv/envp 全部复制到内核自己分配的缓冲区(new_page)里
- 然后再 loader()(这时覆盖用户空间也没事了,因为参数已经在内核里)
- 最后用“内核拷贝”的参数去构造新用户栈
运行Busybox
尝试通过NTerm运行Busybox中的一些简单命令, 比如cat和printenv等. 如果你不清楚这些命令的用法, 可以通过man来查阅它们. 注意不要让这些命令的输出淹没在hello_fun()打印的信息中, 为此你可能需要调整hello_fun()打印信息的频率.
直接变异好之后,在nterm里面加上就行。
超越容量的界限
理解分页细节
- i386不是一个32位的处理器吗, 为什么表项中的基地址信息只有20位, 而不是32位?
- 手册上提到表项(包括CR3)中的基地址都是物理地址, 物理地址是必须的吗? 能否使用虚拟地址?
- 为什么不采用一级页表? 或者说采用一级页表会有什么缺点?
回答: 低20位是页内地址,页机制加上页内地址=物理地址 不行吧?因为虚拟地址(或者逻辑地址)经过分段之后得到线性地址,物理地址分页(就是从页表中取出页基址的部分)是物理地址 因为一个程序的虚拟存储空间有4GB,一个页表4KB,那么需要有10^20个页表项,开销巨大
虚存管理中PIC的好处
我们之前提到, PIC的其中一个好处是可以将代码加载到任意内存位置执行. 如果配合虚存管理, PIC还有什么新的好处呢? (Hint: 动态库已经在享受这些好处了)
回答: 每一个程序都可以独享4GB的存储空间,不会和其他程序相互干扰。(即便他们的虚拟空间相同,但是映射到的物理空间是不同的)
在CPU中加上satp,然后:
#define isa_mmu_check(vaddr, len, type) ((cpu.satp & 0x80000000) ? MMU_TRANSLATE : MMU_DIRECT)
实现imm_translate函数:
paddr_t isa_mmu_translate(vaddr_t vaddr, int len, int type) {
uint32_t vpn1=vaddr>>22;
uint32_t vpn0=(vaddr>>12)&0x3ff;
paddr_t pde_addr=((cpu.satp&0x3fffff)<<12)+vpn1*4;
word_t pde=paddr_read(pde_addr,4);
assert(pde&1);
paddr_t pte_addr=((pde>>10)<<12)+vpn0*4;
word_t pte=paddr_read(pte_addr,4);
assert(pte&1);
paddr_t ppn=pte>>10;
return (ppn<<12)|vaddr&0xfff;
}
之后再uContext构造的时候把
在分页机制上运行Nanos-lite
实现以下内容:
- Nanos-lite的
pg_alloc().pg_alloc()的参数是分配空间的字节数, 但我们保证AM通过回调函数调用pg_alloc()时申请的空间总是页面大小的整数倍, 因此可以通过调用new_page()来实现pg_alloc(). 此外pg_alloc()还需要对分配的页面清零. - VME的
map(). 你可以通过as->ptr获取页目录的基地址. 若需要申请新的页表, 可以通过回调函数pgalloc_usr()向Nanos-lite获取一页空闲的物理页. - 在NEMU中实现分页机制.
由于此时Nanos-lite运行在内核的虚拟地址空间中, 而这些映射又是恒等映射, 因此NEMU的地址转换结果pa必定与va相同. 你可以把这一条件作为assertion加入到NEMU的代码中, 从而帮助你捕捉实现上的bug.
如果你的实现正确, 你会看到仙剑奇侠传也可以成功运行. 如果你对分页机制的细节有疑问, 请RTFM.
分时多任务
问题回答
问:如果在用户进程设置正确的栈指针之前就到来了中断, 我们的系统还能够正确地进行中断处理吗?
答:可以正确处理。
原因如下:
操作系统已预设栈指针:在 Nanos-lite 的 context_uload 函数中,我们已经通过 ucontext 为用户进程创建了初始上下文,并显式地将 pcb->cp->gpr[2] (即 sp 寄存器) 设置为了用户栈的顶部(或带有参数的栈位置)。
调度启动即有效:当系统第一次调度该用户进程时,__am_asm_trap 中的恢复流程(mret 之前)会把这个预设好的 sp 加载到 CPU 的 sp 寄存器中。
中断响应时机:即使中断发生在用户进程 _start 的第一条指令,此时 CPU 的 sp 寄存器也已经是有效的用户栈指针了。RISC-V 处理器的硬件中断是在指令执行边界触发的,在进入 _start 之前,sp 就已经由内核恢复完毕。
因此,__am_asm_trap 保存上下文时,使用的 sp 是有效的,能够正常完成上下文保存和后续的中断处理。
实现方法:
在软件层面,nanos-lite在Context* __am_irq_handle(Context *c) {函数上,加上对于
IRQ_TIMER的检查:
case 0x80000007: ev.event = EVENT_IRQ_TIMER; break;
然后在do_event里面:
case EVENT_IRQ_TIMER:
Log("EVENT_IRQ_TIMER detected");
return schedule(c);
用调度器切换程序实现进程的切换。
 但是实际上并没有触发这个Event,检查发现timer_intr的确是正常地被调用了,但是却没有出现调试信息,发现:
我检查了MIE位,但是在初始化mstatus的时候写的是0x1800,默认MIE位0,改为0x1808,让MIE设置为1即可出现正常的中断
但是实际上并没有触发这个Event,检查发现timer_intr的确是正常地被调用了,但是却没有出现调试信息,发现:
我检查了MIE位,但是在初始化mstatus的时候写的是0x1800,默认MIE位0,改为0x1808,让MIE设置为1即可出现正常的中断
if (cpu.INTR &&(csr(MSTATUS)&0x8)) {
但是却没有出现程序的切换?
尝试用最简单的两个程序进行切换:
void hello_boring(void* arg){
int j=1;
while(1){
j++;
}
}
context_kload(&pcb[0], hello_boring, (void *)1);
context_kload(&pcb[1], hello_boring, (void *)1);
发现一直在执行其中的一个。 多次添加宏打印发现:
word_t isa_query_intr() {
// Log("Fuck %d %d",cpu.INTR,csr(MSTATUS)&0x8);
// if (cpu.INTR &&(csr(MSTATUS)&0x8)) {
if (cpu.INTR) {
Log("Fuck here");
cpu.INTR = false;
return IRQ_TIMER;
}
return INTR_EMPTY;
}
如果把检测逻辑改为只看cpu.INTR,那就可以实现正常的切换,但是使用上面的那个检测逻辑(同时看MIE位)就不行(因为MIE位被置为0,一直没有改回)。
在纠结过后,我选择按照实验手册上说的来操作(把mstatus初始化为0x1800),然后在检查的时候只检查INTR位(后者我不知道对不对。。。)
最后的解决方案是把 MPIE赋值为1,这样在mret之后就可以正确地回来之后MIE为1,从而成功地触发中断:
从而实现调度
基于时间片的进程调度
优先级调度
我们可以修改schedule()的代码, 给仙剑奇侠传分配更多的时间片, 使得仙剑奇侠传调度若干次, 才让hello内核线程调度1次. 这是因为hello内核线程做的事情只是不断地输出字符串, 我们只需要让hello内核线程偶尔进行输出, 以确认它还在运行就可以了.
给每一个进程加上一个权重,虽然简陋,但是能用。
struct {
int Count;
int Weight;
}TimeWeight[4]={
{.Count=0,.Weight=1},
{.Count=0,.Weight=12},
{.Count=0,.Weight=1},
{.Count=0,.Weight=1},
};
Context* schedule(Context *prev) {
int cur_idx=(current>=pcb&¤t <pcb + nr_proc) ? (current - pcb):0;
if (cur_idx >= 0) {
current->cp = prev;
}
int next_idx =cur_idx;
if(--TimeWeight[cur_idx].Count==0){
TimeWeight[cur_idx].Count=TimeWeight[cur_idx].Weight;
next_idx = (cur_idx + 1) % nr_proc;
}
current = &pcb[next_idx];
Log("Schedu Called! Pre idx %d, next idx %d",cur_idx,next_idx);
return current->cp;
}
实现内核栈和用户栈之间的切换
理解上述讲义内容, 修改CTE的代码, 使其支持内核栈和用户栈之间的切换. 你需要了解你的实现中是如何体现上述伪代码的功能, 同时, 根据不同概念变量的性质, 你可能还需要在cte_init()或者kcontext()/ucontext()中对它们进行初始化. 如果你希望在__am_irq_handle()中维护这些概念变量, 必要的时候可以采用内联汇编.
实现后, 让Nanos-lite加载NTerm和hello这两个用户进程, 然后从NTerm启动仙剑奇侠传. 如果你的实现正确, 你将可以看到hello用户进程和NTerm/仙剑奇侠传分时运行. 和之前的效果不同, 这次我们真正实现了两个用户进程的分时运行.
[!NOTE] BUGS 在改trap.S的时候,总是出现错误,莫名奇妙就run不了了,即便checkout到之前的commit重新边编译也是没用。搞得十分痛苦。 (尤其是check回PA3发现PA3的实现貌似也出错了。。。)
BUG修好以后,终于可以run了
编写不朽的传奇
展示你的计算机系统
添加前台程序及其切换功能, 展示你亲手创造的计算机系统.
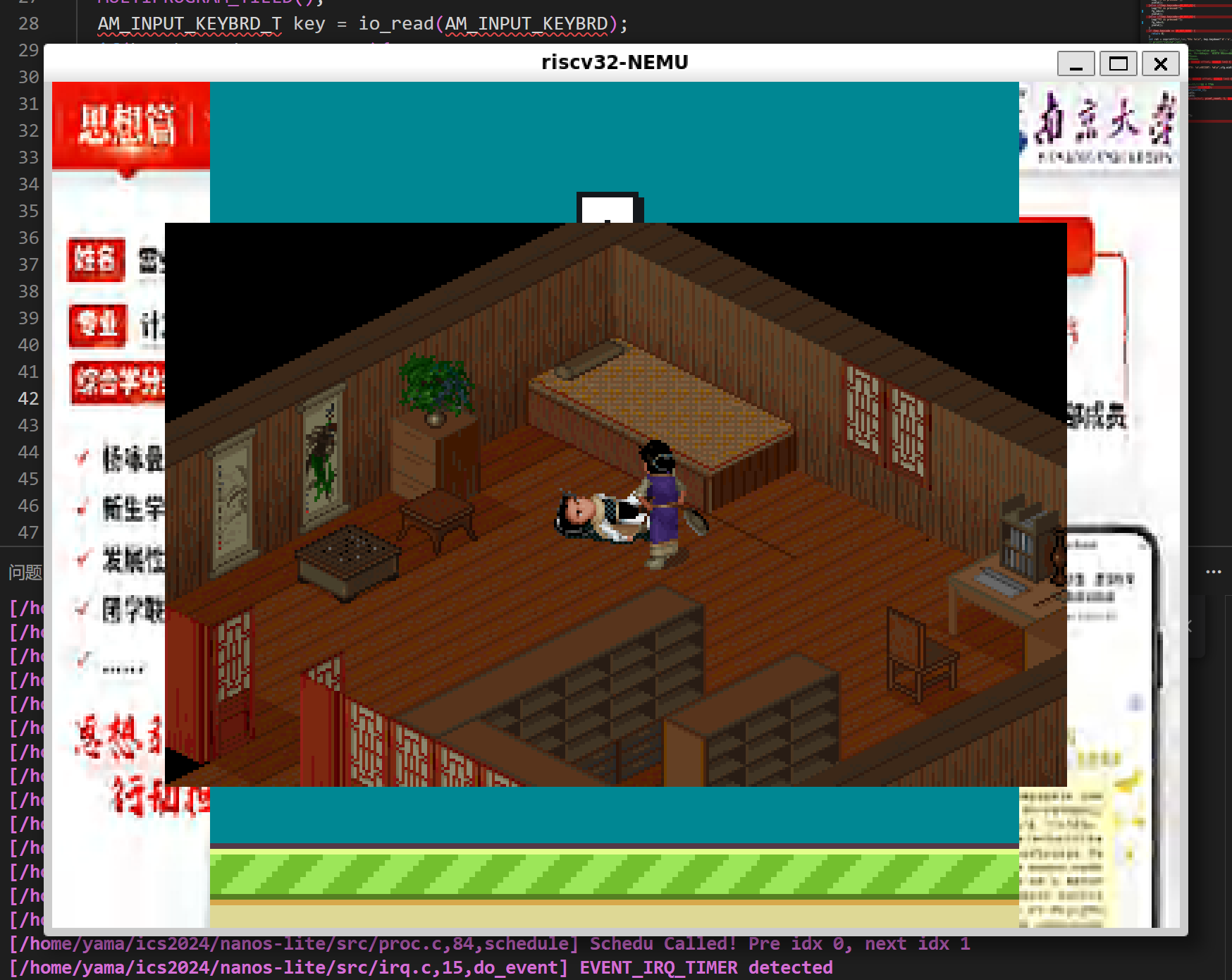
在device.c中,加上对pressF1 F2 F3的检测然后修改一个全局变量fg_idx来控制调度运行哪一个程序
在pro.c中添加调度逻辑即可.
虽然目前绘画有些问题,但是起码work(
必答题
分时多任务的具体过程 请结合代码, 解释分页机制和硬件中断是如何支撑仙剑奇侠传和hello程序在我们的计算机系统(Nanos-lite, AM, NEMU)中分时运行的.
分页机制 ucontext()在创建用户进程上下文时,会把该进程的页目录指针写进Context->pdir并标记它将返回到用户态(np=USER):
Context *ucontext(AddrSpace *as, Area kstack, void *entry) {
Context* context = (Context*)(kstack.end - sizeof(Context));
memset(context, 0, sizeof(Context));
context->mepc=(uintptr_t)entry;
context->mstatus = 0x1880; // MPIE = 1, MPP = 11
context->pdir = as->ptr;
context->np = 0; // USER
return context;
}
不同的进程会映射到不同的页面,protect() 会新建用户页目录,并把内核页表拷贝进去,保证所有进程都能看到内核映射:
void protect(AddrSpace *as) {
PTE *updir = (PTE*)(pgalloc_usr(PGSIZE));
as->ptr = updir;
as->area = USER_SPACE;
as->pgsize = PGSIZE;
memcpy(updir, kas.ptr, PGSIZE);
}
在一次 trap/中断处理结束前,AM 会调用 __am_switch(c),用 Context->pdir 去写 satp,从而把 CPU 的虚拟地址空间切到“即将运行的那个进程”的页表:
void __am_get_cur_as(Context *c) {
c->pdir = (vme_enable ? (void *)get_satp() : NULL);
}
void __am_switch(Context *c) {
if (vme_enable && c->pdir != NULL && c->pdir != kas.ptr) {
set_satp(c->pdir);
}
}
这样就使得CPU当前的页面映射是和进程相关的,在运行不同程序的时候,映射到不同的页面。实现分页机制
硬件中断 在NEMu中实现了一个定时触发的IRQ_TIMER异常,当触发这个异常之后,
static Context* do_event(Event e, Context* c) {
switch (e.event) {
case EVENT_YIELD:
return schedule(c);
// Log("[Event Detected] yield ");
break;
case EVENT_SYSCALL:
// Log("[Event Detected] syscall id=%d ",c->GPR1);
do_syscall(c);
break;
case EVENT_IRQ_TIMER:
Log("EVENT_IRQ_TIMER detected");
return schedule(c);
case EVENT_PAGEFAULT:
case EVENT_IRQ_IODEV:
case EVENT_NULL:
case EVENT_ERROR:
default: panic("Unhandled event ID = %d", e.event);
}
return c;
}
在do_event中,触发schedule调度器,在pro.c中的切换进程:
Context* schedule(Context *prev) {
int cur_idx = (current >= pcb && current < pcb + nr_proc) ? (current - pcb) : -1;
if (cur_idx >= 0) current->cp = prev;
int next_idx;
if (cur_idx == PROC0) {
//如果是后台程序,那就调度到前台
next_idx = fg_idx;
} else {
next_idx = PROC0;
}
current = &pcb[next_idx];
Log("Schedu Called! Pre idx %d, next idx %d",cur_idx,next_idx);
return current->cp;
}
不过我写的这个已经是后面实现了简陋的F1 F2 F3切换程序的版本。
在硬件中: NEMU 把 mcause=IRQ_TIMER(0x80000007)、mepc=epc,并按 RISC-V 规则更新 mstatus,最后返回 mtvec 作为异常入口地址:
csr(MCAUSE) = NO;
csr(MEPC) = epc;
word_t mstatus = csr(MSTATUS);
mstatus = (mstatus & ~(1 << 7)) | (((mstatus >> 3) & 1) << 7); // MPIE = MIE
mstatus = mstatus & ~(1 << 3); // MIE = 0
mstatus = (mstatus & ~(0x3 << 11)) | (0x3 << 11); // MPP = 11 (M-mode)
csr(MSTATUS) = mstatus;
return csr(MTVEC);
- AM 把 mtvec 指向 __am_asm_trap,统一处理 ecall/中断 初始化时设置 mtvec=__am_asm_trap,并把 mscratch=0(用于后续内核栈切换):
- 在trap.S 完成“栈切换 + 保存上下文 + 调 C 处理函数 + 恢复上下文 + mret” 关键点是 csrrw sp, mscratch, sp:当从用户态陷入时,mscratch 里放的是内核栈指针(ksp),于是把 sp 切到内核栈;随后保存寄存器/CSR,再 call __am_irq_handle,最后 mret 返回。
分时运行 为了实现hello和pal的分时运行,就需要两个进程轮流的切换,需要定时地触发中断,然后让调度器来对两个进程进程分配。 两个进程受益于前面分页机制的存在(运行的进程决定了内存的映射,即便相同的地址,也会映射到不同的地址空间) 1) 用户进程在用户态运行
- hello/pal 都在用户虚拟地址 0x4000.... 区间执行(由分页机制保证每个进程各自独立映射)。
定时地发生NEMU时钟中断,进入 AM trap.S 入口,保存现场
__am_asm_trap,trap.S 把 sp 切到内核栈,并把通用寄存器、mcause/mstatus/mepc 保存成一个 Context 结构体(见 trap.S 引用)。 4) AM 在__am_irq_handle中识别事件并交给 Nanos-lite __am_irq_handle读取 c->mcause,把 0x80000007 识别成 EVENT_IRQ_TIMER:
switch (c->mcause) {
case 0x80000007: ev.event = EVENT_IRQ_TIMER; break;
case 0xb: ... ev.event = EVENT_YIELD / EVENT_SYSCALL; c->mepc += 4; break;
}
c = user_handler(ev, c);
__am_switch(c);
return c;
Nanos-lite 的 do_event() 在时钟中断上调用 schedule() 选下一个进程 于是hello和pal就可以协同地工作,一边在终端上打印hello world,一边在sdl窗口中展示pal的内容。
理解计算机系统 尝试在Linux中编写并运行以下程序:
int main() {
char *p = "abc";
p[0] = 'A';
return 0;
}
你会看到程序因为往只读字符串进行写入而触发了段错误. 请你根据学习的知识和工具, 从程序, 编译器, 链接器, 运行时环境, 操作系统和硬件等视角分析"字符串的写保护机制是如何实现的". 换句话说, 上述程序在执行p[0] = 'A'的时候, 计算机系统究竟发生了什么而引发段错误? 计算机系统又是如何保证段错误会发生? 如何使用合适的工具来证明你的想法?
 把代码编译运行之后,发现出现了SegmentFault。
结合ICS刚刚考完试的记忆:
把代码编译运行之后,发现出现了SegmentFault。
结合ICS刚刚考完试的记忆:
- 因为
char*p指向的是一个只读的字符串(其在可重定位文件的.rodata端,在可执行文件的只读代码段),其权限是不可写的。 - 当执行到p[0]='A'的时候,尝试在一个只读的地方写,因此出现
#13 PF段错误 详细地来讲是这样的: 当我在shell中敲下gcc的指令之后,gcc程序对源代码进行了: - 预处理为.i,编译为.s,汇编为机器代码.o,链接成可执行文件tmp.out
之后,我输出
./tmp.out之后,shell进程读取到我的字符串,解析出来之后,发现是要执行tmp,out这个文件。于是fork一份当前进程,然后execve执行这个程序。
objdump -d得到汇编指令为:
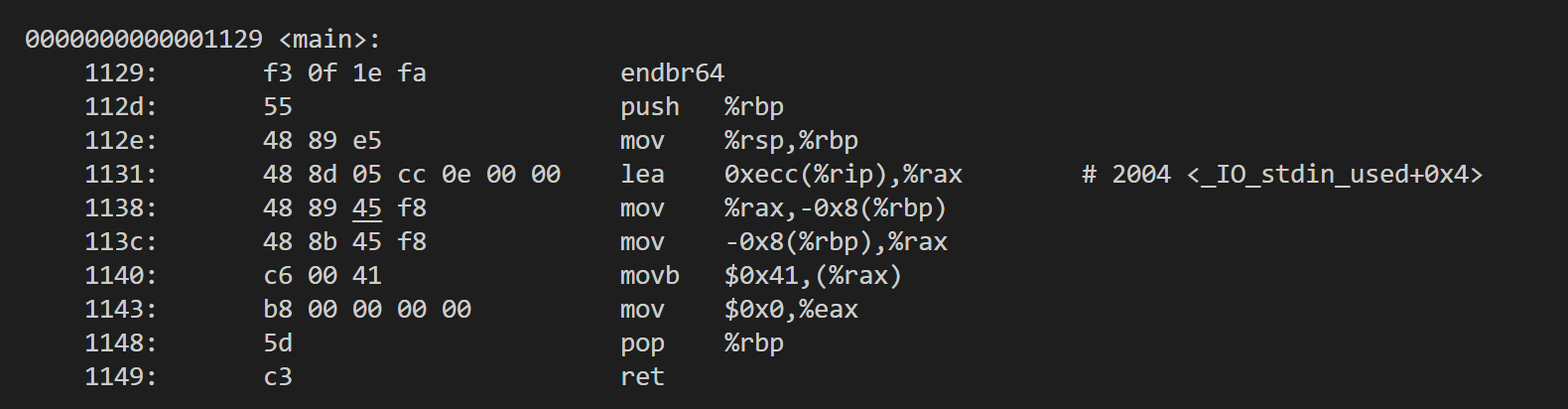 可见,1140处的指令尝试将
可见,1140处的指令尝试将A(ASCII码为0x41)写入M[rax]。
打开pwngdb进行调试
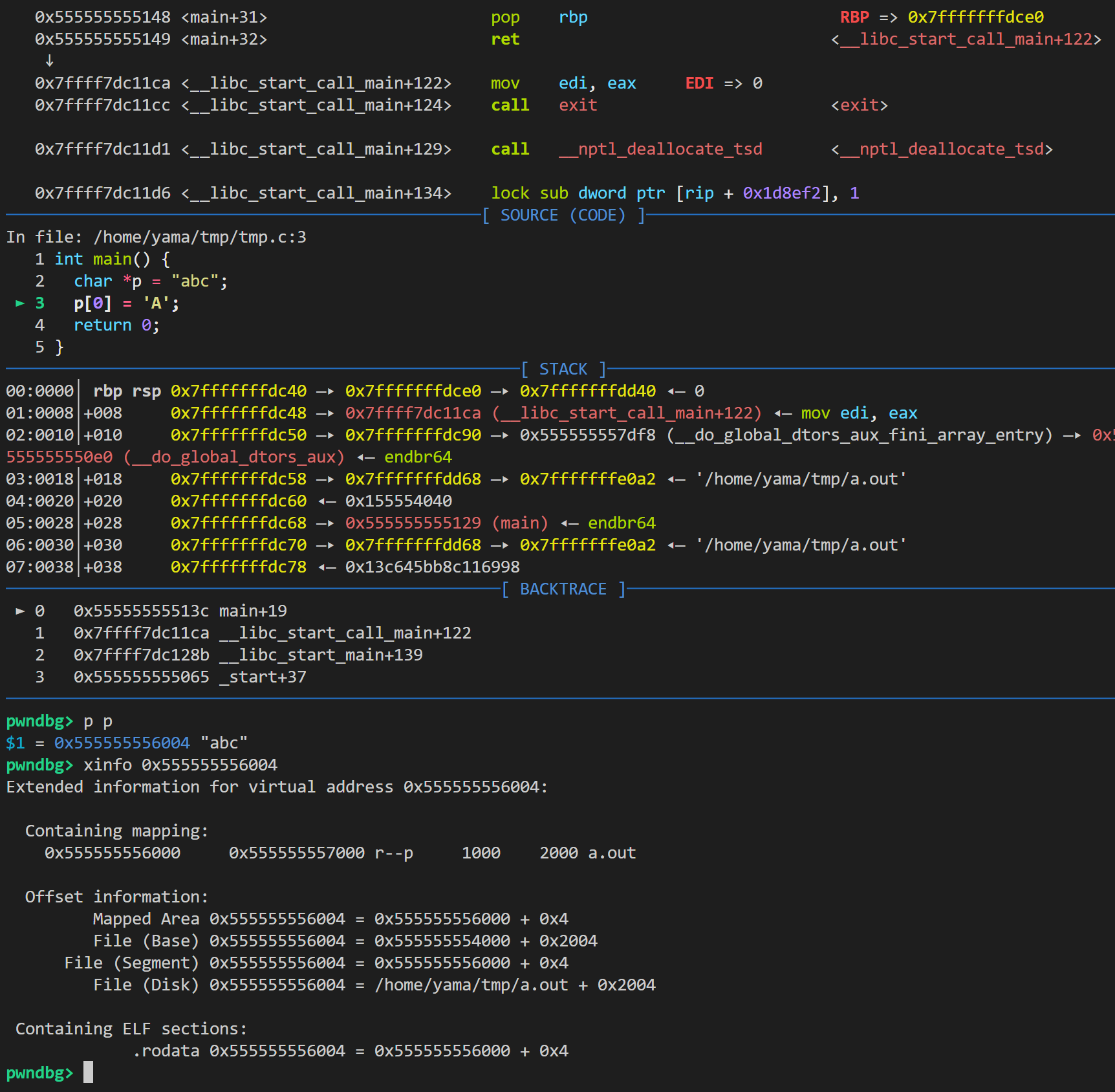 发现p的地址是在.rodata起始位置的四个字节后。所以,当然是只读。因此,写的时候会出现页故障。
发现p的地址是在.rodata起始位置的四个字节后。所以,当然是只读。因此,写的时候会出现页故障。
前面已经分析,并且验证了我的猜想,下面是更详细的版本。 下面开始背书环节:
- 当MMU从CPU中得到目标地址的线性地址,此后,通过分段机制转换为虚拟地址,由于linux对分段机制做了简化,页基址为0. 所以线性地址就是虚拟地址,然后通过Page Table walk,遍历逐级页表,找到最终页表的地址。发现最后一页(PTE)是只读的,但是尝试写操作,因此报
#14PF异常。 - CPU检测到
#14PG异常之后,从IDTR指向的IDT中取出第14号项,作为中断描述符表,完成栈的切换(把原本的Stack Seagment和RSP保存在内核栈中)和上下文保存(把EFLAGS、RIP等上下文信息也保存在内核栈)之后调转到对于异常处理程序中 - 在中断异常处理程序中,发现触发PF的原因是,尝试对只读页面进行写操作,属于是不可恢复的异常,因此向原进程发送一个SEVSEGV信号。
- 回到原先用户态之后,进入到SEGSEGV信号处理函数中,在终端上打印CoreDump等信息,并结束进程。
写在最后: 我写这段话的时候是2026年1月13日,距离ddl还有12分钟,提交应该是来得及的。所以我想写写我对PA的感悟。 从最开始写PA,我给自己下的要求是要把讲义上的所有内容都做了(指的是非必答题) 然后越到后面(特别是到PA3的时候,我已经有些hold不住了)我写PA的意愿就越来越弱,直到完全变成一个DDL战士。 对于网络公开的内容,也只能辅助到PA3左右,PA4 的资料很少,也不一定对我有帮助。很多BUG都是靠AI辅助找到的,不过AI对于像NEMU之类的大project感觉理解能力还有待提升。时间要不够了,只能停笔了,不然ddl就赶不上了、、、
 chatGPT给我的年度诗篇 ```text
chatGPT给我的年度诗篇 ```text