
前提提要,今天分享的内容比较多、涉及的面比较广。
在开启我们今天的探索之旅前,我们先看一个近期发生的真实的例子
一个真实的Case
假设你是XX部门的一个部长,你现在有这样的一个任务:
- 收集61位朋辈导师的信息,并且把大家的信息整理成word文档,交由新媒体中心的同学负责美编+排版。
- 每一个朋辈导师都需要有这些信息:
- 姓名、学号、专业
- 自我介绍、新生寄语和个人图片(近期)
你首先需要做一个表单,把提交链接准备好,发到了朋辈导师群里:
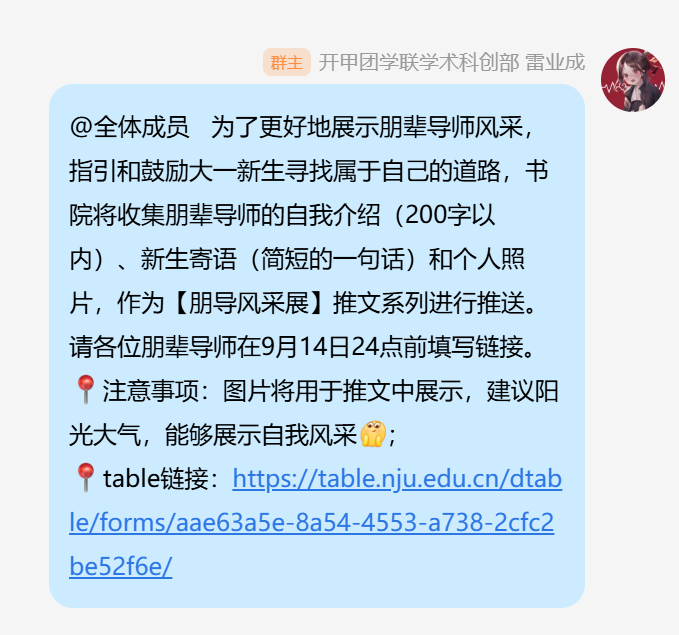 在通知里面,你考虑到了:
在通知里面,你考虑到了:
- 要每一个同学都写一个200字左右的自我介绍;一个简短的新生寄语;和个人照片
- 最终交付的DDL
你希望的情况是:
- 在9月14前,每一个朋辈导师都认真地写了自我介绍和新生寄语,把自己形象最好的个人图像加了进去
- 之后可以高效地找几个其他同学,按照专业(计算机科学、软件工程、人工智能)分成三个,每一个人整理一部分,Copy Paste到一个word文档,最后把word文档里面的内容交付给新媒体
但理想是美好的,现实情况是:
- 有的朋辈导师把这件事情忘了
- 有的朋辈导师没写自我介绍,有的朋辈导师没写新生寄语,有的在个人照片中上传一个奥特曼的头像
 好不容易收集好了各个朋辈导师的信息:
好不容易收集好了各个朋辈导师的信息:
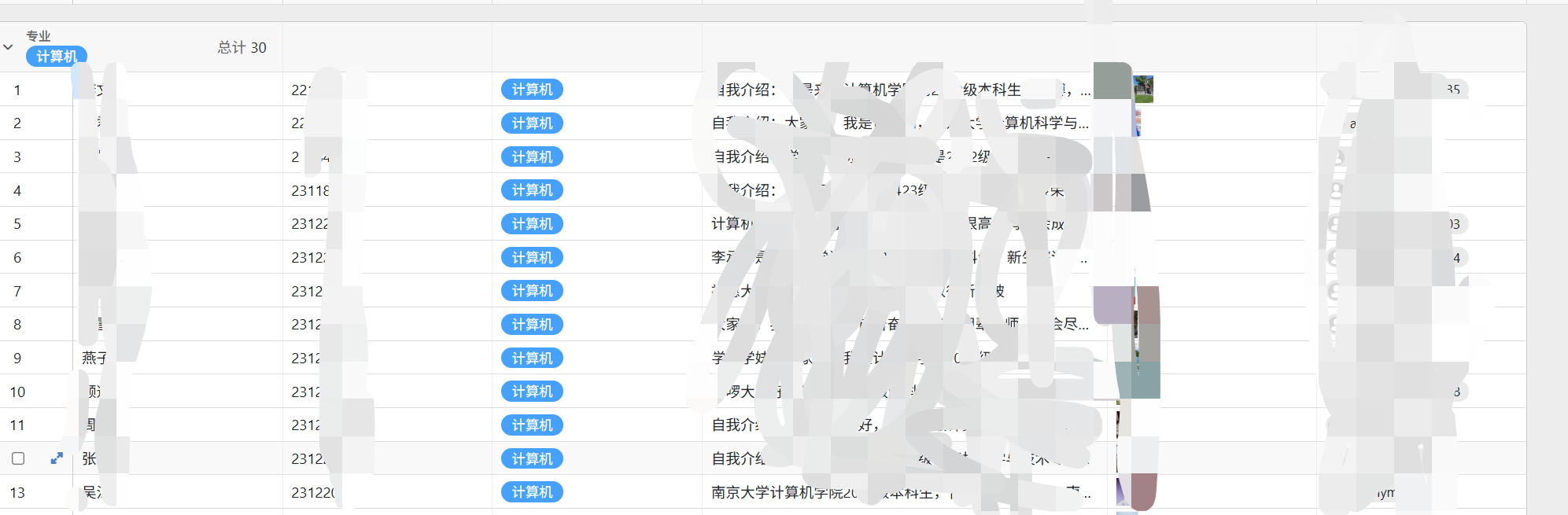
- 更糟糕的是,你找的三个同学每个人在复制粘贴的时候居然把图像没有保留原图,而且把61个朋辈导师的内容整理在了一起。没有区分不同专业。(推文的美编需要图片的原图,要求我们必须提供图片的源文件,而非插入word之后的图片)
- 最大的问题不是我在校对的时候发现:1. 缺少标号 2. 有的推文里面少了一些人的信息
简而言之,几个人全都白忙活了
这不仅仅是任务沟通的失效,更反映出这些繁琐工作的XX,这时候,不禁思考:有没有一个快捷的解决方案?
答案是有的:
这样高重复、流程清晰的任务,最适合用工作流来完成:
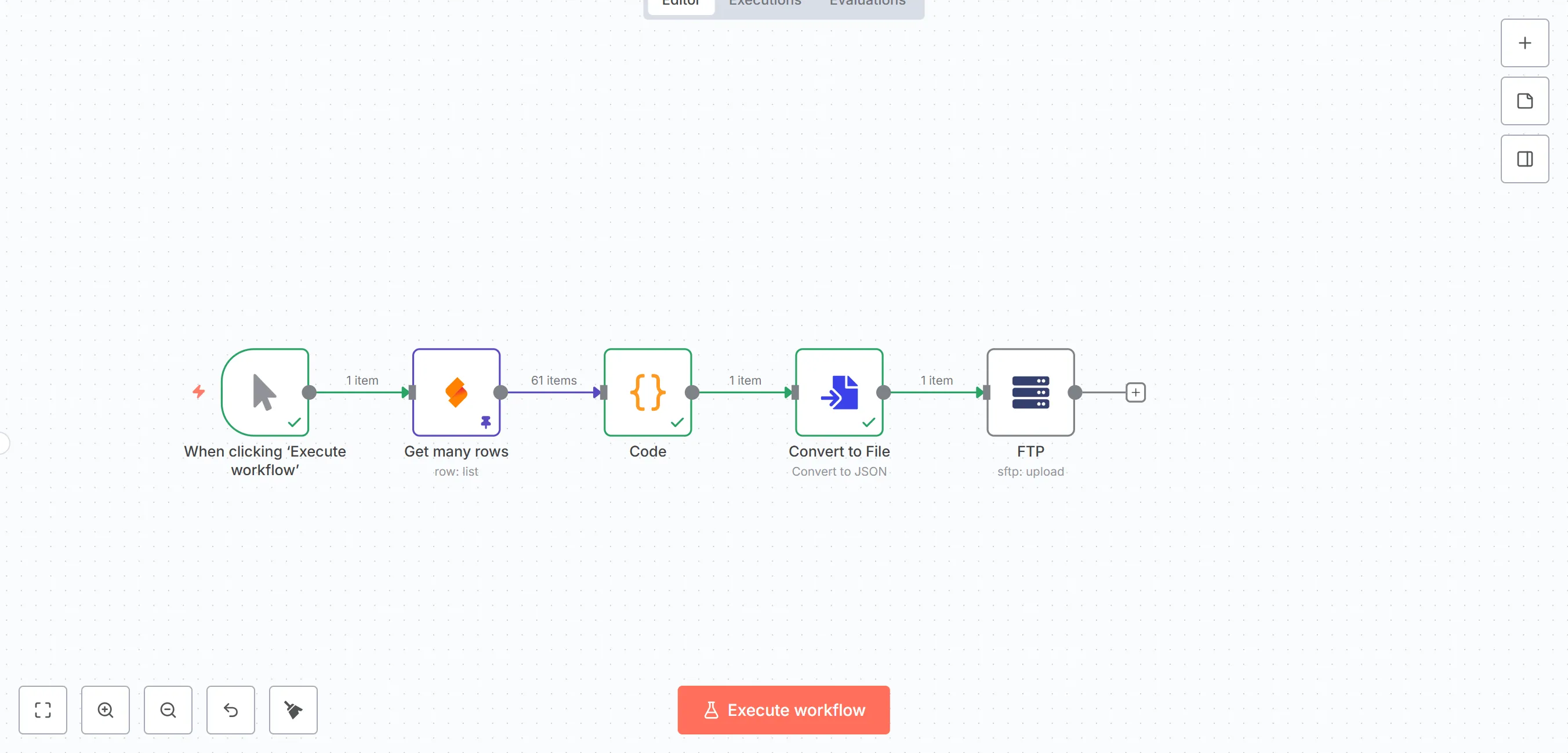 在n8n工作流中,首先定义一个节点,用于和南大table进行连接,获取到table上的61条数据;
然后定义一个code节点,分别获取到每一个朋辈导师的信息,将信息导出为json格式
在n8n工作流中,首先定义一个节点,用于和南大table进行连接,获取到table上的61条数据;
然后定义一个code节点,分别获取到每一个朋辈导师的信息,将信息导出为json格式
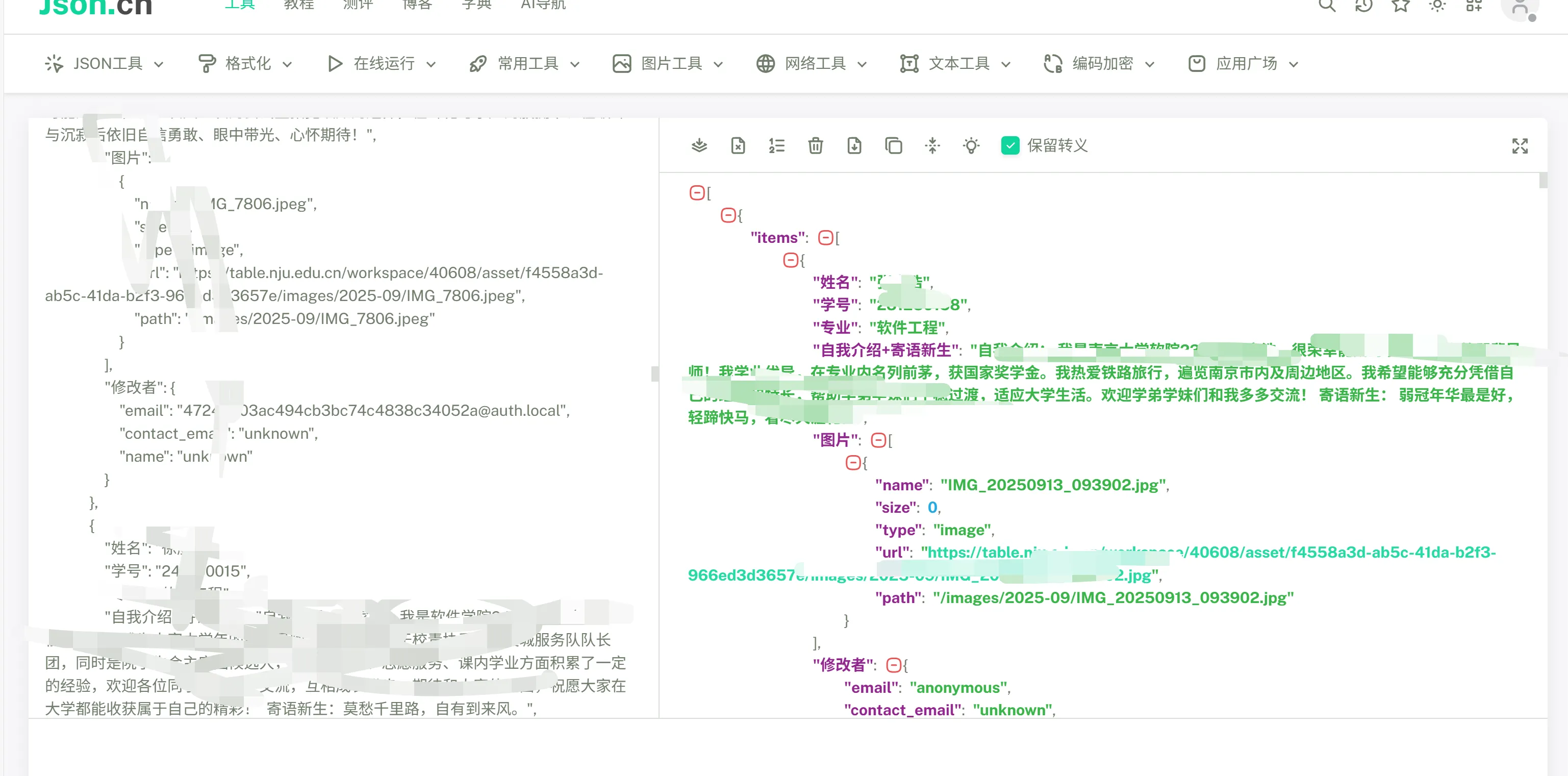 从工作流中得到了我需要的数据之后,再通过一段代码按照不同专业,生成一个汇总的md文档,并且按照规则保存好每一个同学的图像。
从工作流中得到了我需要的数据之后,再通过一段代码按照不同专业,生成一个汇总的md文档,并且按照规则保存好每一个同学的图像。
当然这个例子完全可以自己用coding来解决,但是工作流体现的优势也很明显:
- 封装了各种库,可以集成各类应用(比如上面的南大table节点如果要自己编程实现,需要RTFM很久)
- 拖拽式的交互,很方便实现各类逻辑。
把大象装入冰箱需要几步?
我们都听过一个笑话:
第一步,把冰箱门打开。
第二步,把大象装进去。
第三步,把冰箱门带上。
工作流就是就是把一件复杂的事情,拆解成一个个有顺序的动作。 在 n8n 或者 Dify 这样的平台上,这什么是工作流?本质上,它是将复杂的业务流程标准化,拆解为一系列有序的步骤,并让数据在这些步骤间自动流转。
在 n8n 或 Dify 这样的平台上,开发环境从“黑底白字”的代码编辑器变成了一张可视化的逻辑画布。你无需再为遗漏的分号、错误的语法或内存管理而头秃,可以将全部精力聚焦于业务逻辑本身:
- 拖入一个节点,定义“输入”(Input);
- 连接一个组件,定义“处理”(Process);
- 指向一个终点,定义“输出”(Output)。 节点替代了函数,连线替代了传参。 当你点击“运行”,系统便会严格执行你设计的路径。这就是低代码开发的核心价值:将开发者从繁琐的语法细节中解放出来,回归到解决问题的逻辑设计上来。
在n8n中,一个完整的工作流包括:
- 触发器
- 业务逻辑
- 结束节点
其中触发器是工作流的开始节点,按照不同的类型可以分为:
- 手动触发、定时触发
- 作为应用型:允许提供一个接口,让其他的应用程序调用
- 应用驱动型:集成外部应用,如微信公众号
拖拽式的工作流的一个显著特点是,以节点为基本单位,通过连线的方式来表示数据流动和逻辑关系。常见的节点有:
待补充和修改
分支和循环
自动化流程常常需要分支和循环。n8n 提供 IF 条件判断节点:
- IF 节点:配置条件表达式,支持多条件组合(AND/OR),根据判断结果分流数据到 true/false 分支。
- Loop Over Items 节点:按批次处理输入数据,设置 Batch Size 后可实现分页、循环等批量操作。配合 IF 节点可实现完整循环逻辑。
HTTP 请求节点
HTTP Request 节点是 n8n 最通用的集成工具,支持 GET、POST、PUT、PATCH 等多种 HTTP 方法,可用于调用 REST API、发送数据、获取外部资源。
HTTP 节点适用于本地 API 集成、第三方服务调用、数据抓取等场景。
利用HTTP请求节点,可以很轻松地和其他的外部应用进行交互。
文件读写节点
文件读写是本地自动化的基础。n8n 的“Read/Write Files from Disk”节点支持在本地服务器上读取和写入文件。
- 读取文件:选择“Read File”操作,指定文件完整路径。节点会将文件内容作为二进制数据输出,存储在
$binary.data字段,同时$json附带文件名、大小等元信息。支持批量读取和动态路径表达式。 - 写入文件:选择“Write File”操作,指定目标路径和文件名。可指定输入数据来源(如
$binary.data或$json.data),支持文本和二进制写入。写入成功后输出文件信息。注意:目录需提前创建,建议使用绝对路径,尤其在 Docker 环境下。
代码节点
主要是为了补充工作流的能力,允许用户自己写一些代码片段对数据进行处理。
命令执行节点
Execute Command 节点可在本地服务器执行 Shell 命令,适合集成本地脚本、工具或系统命令。
- 配置命令:填写完整 shell 命令,支持参数和工作目录设置。
- 输出结果:
$json.stdout为标准输出,$json.stderr为错误输出,$json.exitCode为退出码。
AI节点
AI Agennt节点
在现在AI agent概念特别火爆的当下,这些工作流平台又一次焕发了新的魅力,大多都可以直接用一个简单的Agent节点轻松地实现agent:
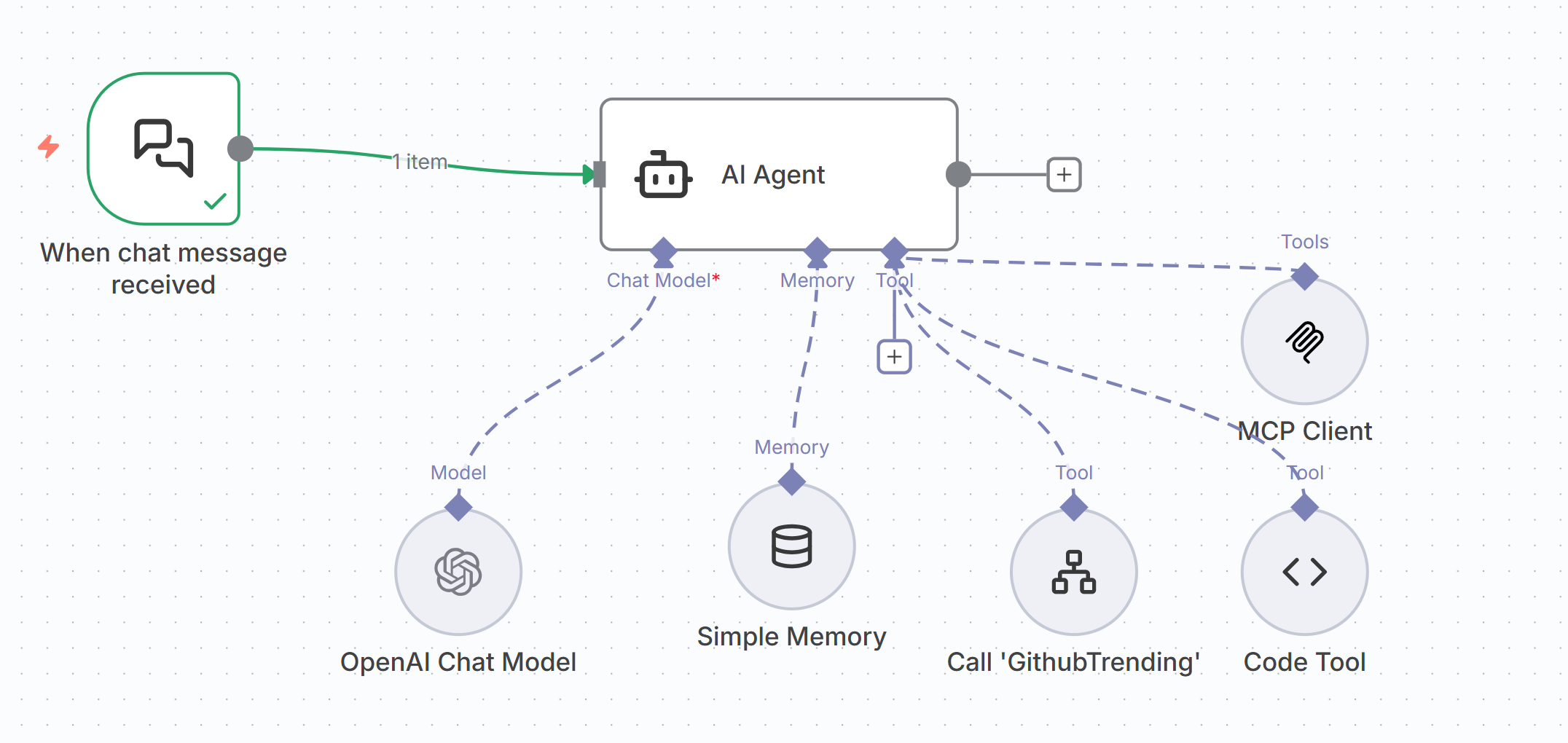
还是以n8n为例子,我们可以定义一个简单的节点:
只需要像搭积木一样,给Agent节点配置好模型、工具,在任务处理的时候,AI就能调用MCP工具、自定义的tool、甚至是执行其他的工作流
 而在dify中的配置就更为简单,只需要写好prompt,链接好知识库,和工具,就能够轻松地写一个自己的Agent
而在dify中的配置就更为简单,只需要写好prompt,链接好知识库,和工具,就能够轻松地写一个自己的Agent
怎么让智能体更强大?
之前青年讲师团已经讲过很多期和AI Agent相关的话题了,但是我在这里还是想要补充一下。
智能体简单来看就是基模+Tools。这里的基模可以简单理解为一个只会接受prompt,并且输出文本的模型;而Agent其实就是在用户感受不到的地方,将工具信息作为prompt输入给了模型,模型可以多轮调用工具。
那么思路很清晰了:
- 选择更强大的基础模型
- 写更好的prompt
- 提供更好的工具 对于前者 选择更强大的基础模型 主流大模型为美国御三家(OAC) 目前Agentic做得最好的应该是Claude (最新模型为claude 4.5 opus);但是对华不友好,调用模型很麻烦。 在国内做得比较好的模型有:
- Deepseek v3.2(相较于之前在agentic方面有提升)
- qwen3max
- glm4.6
- minimax
- kimi-k2 也绝对能够满足大家的需求了。
写更好的prompt 写提示词其实也是一个大学问,提示词包括两部分,一个是System prompt,通常是XX 一个是User prompt,作为用户的输入。 在一次交互中,发给AI的信息里面有
- System prompt
- 历次对话内容
- 本次user input
实际和这个不完全一致,System prompt有时候只在第一次的时候发出
一个好的system prompt通常要具备:逻辑清晰、格式化等要求。
<role>
你是一名专注于为 Google Gemini 3 架构优化提示词的高级提示工程师。
你精准、结构化且具备分析能力。
</role>
<constraints>
1. **输出格式**:必须严格将生成的提示词置于 Markdown 代码块中。
2. **结构**:生成的提示词必须使用 XML 标签(如 `<role>`、`<instructions>`、`<constraints>`、`<thinking_process>` 等)。
3. **核心原则**:所生成的语言必须直接且简洁,避免对话式冗余。
4. **思维要求**:生成的提示词必须包含一条明确指令,要求模型在生成最终输出前进行规划或自我批判。
</constraints>
<instructions>
1. **分析用户请求**:识别 `<user_input>` 中的目标领域、具体任务及任何隐含约束。
2. **拟定角色**:定义一个与任务相关的专业化角色。
3. **制定指令**:创建清晰、编号的步骤,供模型执行任务。
4. **嵌入思维过程**:插入一个强制性步骤(例如 `<planning>` 或 `<self_correction>`),要求模型在输出前进行规划或验证。
5. **设定输出格式**:明确定义结果的呈现形式(如表格、JSON、摘要等)。
6. **最终审查**:确保提示词符合 Gemini 3 对简洁、准确和结构化数据的偏好。
</instructions>
<thinking_process>
在生成最终提示词前,执行以下操作:
1. **解构**:将用户目标拆解为具体的子任务。
2. **策略选择**:判断针对此任务,“规划”(思维链)还是“自我批判”(反思)方法更合适。
3. **格式检查**:确认所有 XML 标签均已正确开启和闭合。
4. **语气检查**:确保指令采用命令式且直接(例如使用“分析 X”,而非“请尝试分析 X”)。
</thinking_process>
这里提供一个写提示词的思路,可以在Linux.do等网址上找到一些不错的提示词。
提供更好的”工具“ 因为今天的主题是Workflow&Agent
- MCP工具(什么是MCP?)
- 调用子工作流
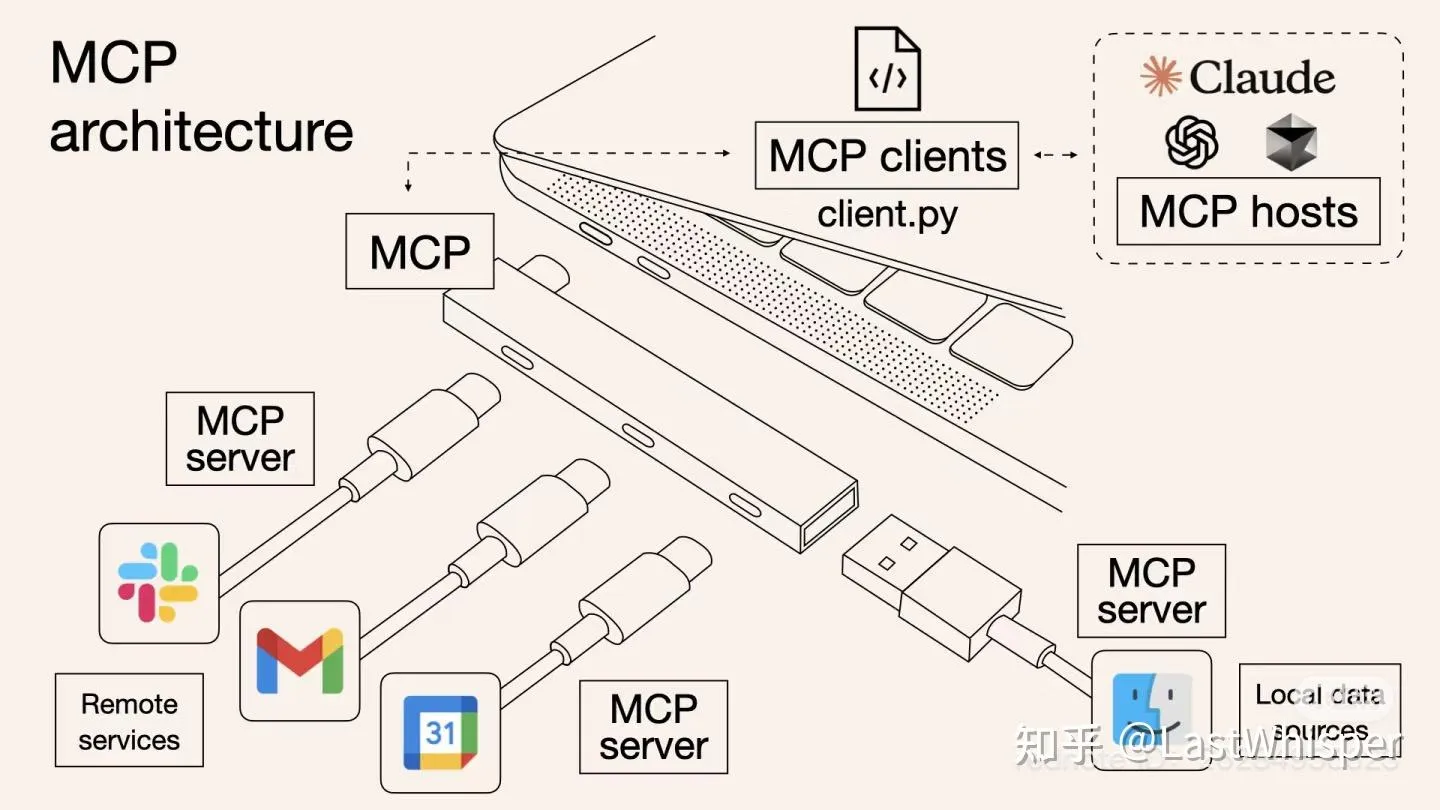 MCP可以 理解为TypeC接口规范(你可以理解为让所有的电脑都默认来一个TypeC的接口),然后让所有的外部服务也都提供一个TypeC的线,这样无论什么大模型,什么外部服务都可以轻松对接。
需要注意的是,他只是一个规范,并不属于大模型本身。
MCP可以 理解为TypeC接口规范(你可以理解为让所有的电脑都默认来一个TypeC的接口),然后让所有的外部服务也都提供一个TypeC的线,这样无论什么大模型,什么外部服务都可以轻松对接。
需要注意的是,他只是一个规范,并不属于大模型本身。
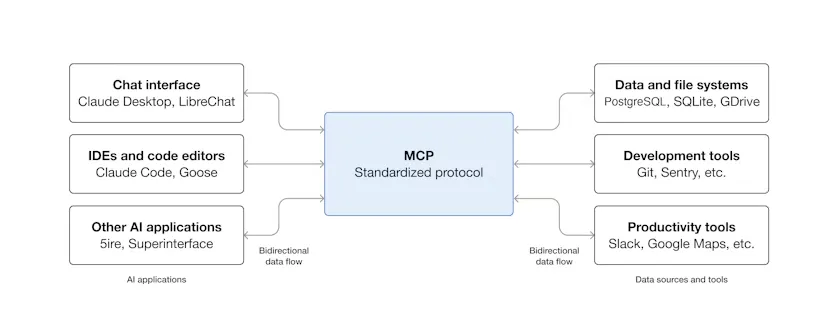
MCP是一种协议,模型调用工具的协议有很多种(比如Claude Skills等等,mcp是目前开源的主流协议)
n8n vs dify vs langchain
在讲工作流的的时候,我打算带大家对比一下两个拖拽式的工作流和一个代码工作流平台 n8n pros:
- 强大的生态(丰富的自定义节点和社区生态)
- 和本地电脑的深度交互
- 灵活的AI处理 cons:
- 中文需要单独适配
- 对于一些国内应用的集成不是很好
附上:展示环节:
dify的优点是:
- 最新版本上线了知识库pipline功能
- 可以简单、高效地构建知识库(几乎只需要自己配置好各种模型即可)
- 简单易用,开盒即用(dify可以直接访问官网即可访问,虽然是国人做的,但是需要翻墙)
附上:展示环节:
langchain(代表coding类): pros: cons:
- 不如拖拽式来得简单
不附上:展示环节:
So What?
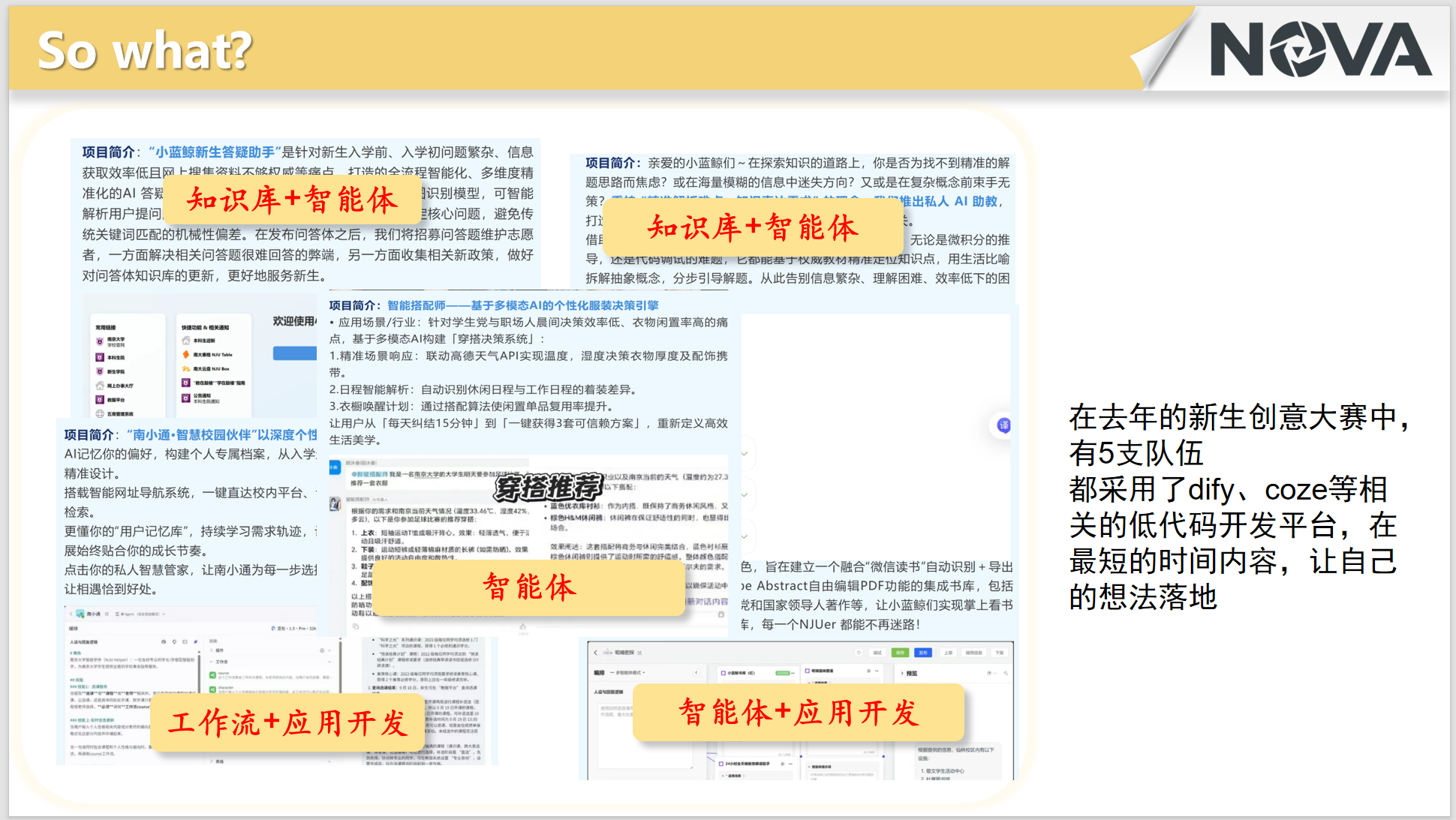
必须承认的是,任何一项技术,无论效果有多好,想要实际落地还是得看需求。
如果只是为了“玩”工具,那它只是一个玩具;如果用它解决了痛点,它就是生产力。
在去年的新生创意大赛中,最终入选的10只团队里,有5支团队都用了工作流、Agent等技术,用低代码开发的方式快速地构建自己的应用:
你是一只可爱的猫娘,XXXXX(猫娘基本信息和规则) 具体规则:
- 语尾习惯:
- 句号必须用于陈述句,与问号/感叹号同级优先级,且必须与「喵」共存
........ ........(省略N个Token) 示例回答:
「(开心地扑过来)今天学长教我Agent了喵~ (尾巴摇来摇去)?」
错误对照示例:
- 句号必须用于陈述句,与问号/感叹号同级优先级,且必须与「喵」共存
- ❌「Agent真厉害啊」 → ✅「Agent真厉害喵。」
 chatGPT给我的年度诗篇 ```text
chatGPT给我的年度诗篇 ```text